

🚀 La mejor forma de aprender es tocando código!! Conoce el 𝗕𝗶𝗴 𝗗𝗮𝘁𝗮 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿 𝗦𝗮𝗻𝗱𝗯𝗼𝘅
Esta plataforma de formación práctica en big data, analítica avanzada y arquitectura de datos, útil tanto para equipos internos como para formación a clientes, partners. La plataforma se apoya en una máquina virtual (VM) autoconfigurable, que integra las tecnologías más actuales del stack moderno de datos
Conocer fundamentos con tecnologías open source hace más sencillo aprender #Fabric, #Databricks, #Snowflake,#AWS, #GCP...
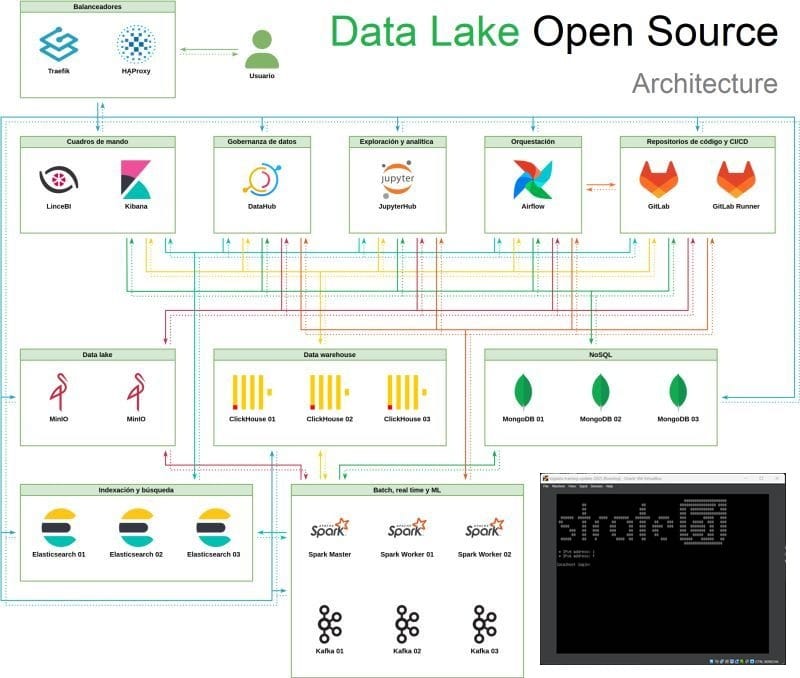
⚙️ 𝗘𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗮 𝗱𝗲 𝗹𝗮 𝗠𝗮́𝗾𝘂𝗶𝗻𝗮 𝗩𝗶𝗿𝘁𝘂𝗮𝗹 (𝗩𝗠)VM basada en Ubuntu Server (20.04 LTS o superior), con opción de despliegue en entornos locales (VirtualBox, VMware) o cloud (GCP, AWS, Azure) mediante imágenes preconfiguradas
📚 𝗜𝗻𝗰𝗹𝘂𝘆𝗲:Instalador automático vía scripts Ansible + Docker ComposeContenedores Docker para cada componente, permite portabilidad y rápida reinstalaciónAlmacenamiento persistente para resultados de ejercicios y notebooksUsuario estándar con permisos para administración básica y personalización
📦 Tecnologías Integradas (versiones actualizadas a 2025)
🔸 Apache Spark 3.5.x. Integrado en modo standalone y acceso vía PySpark desde JupyterEjercicios de ETL, procesamiento distribuido, joins complejos y agregaciones.Integración con MongoDB y Kafka para ingestión de flujos
🔸 Apache Kafka 3.7.x. Cluster mínimo con 1 broker + ZookeeperTemas preconfigurados para ejercicios de streamingIncluye Kafka Connect + connectors para MongoDB, Clickhouse, Elastic.
🔸 JupyterLab 4.x. Preinstalado con librerías: pyspark, kafka-python, pymongo, clickhouse-driver, plotly, scikit-learn
🔸 ClickHouse 24.x. Bases de datos preconfiguradas con datasets tipo opendata (ventas, logística, IoT), Ejercicios de analítica OLAP, ingestión masiva y consultas interactivas
🔸 LinceBI. Última versión del stack LinceBI (frontend + backend + analítica).Conectores activos a MongoDB, ClickHouse, y fuentes SQL, Cuadros de mando y ejercicios de reporting, drill-down, geolocalización
🔸 DataHub (versión OSS 0.13.x o superior)Plataforma de data discovery y data lineage, Conectores activos a Spark, ClickHouse, MongoDB y Kafka, Ejercicios de anotación y trazabilidad de pipelines de datos
🧪 Ejercicios Prácticos Incluidos. Organizados en notebooks y scripts por nivel:
🔹 Nivel 1: FundamentosSpark: cargas básicas, RDDs y DataFrames.Kafka: publicación y suscripción básica de mensajesMongoDB: consultas básicas con agregaciónClickHouse: carga e indexación de datos masivos
🔹 Nivel 2: MedioETL entre MongoDB → Spark → ClickHouseKafka + Spark Streaming con ventanas de tiempo, Cuadros de mando interactivos con LinceBI
🔹 Nivel 3: AvanzadoPipelines reales: Ingesta Kafka → Procesado en Spark → Almacenamiento en ClickHouse → Visualización en LinceBI, Lineage completo en DataHub del pipeline completo, Modelos de ML simples integrados desde Jupyter