Hace unos días os contábamos:
 Emilio
Emilio
Pues hoy venimos con muchos más trucos y tips técnicos (más avanzados) de una de las mejores herramienas ETL: Talend
1. Validación y filtrado de datos
Resumen: El propósito de esta sección es explicar la validación de datos mediante Talend Open Studio.
Dificultad: 3
Utilidad: 5
Desarrollo: TOS valida datos de manera automática. Por ejemplo, detecta si en un campo entero se introduce un valor correcto (int) o un valor incorrecto (string, boolean, etc.).
Sin embargo, se puede llevar la validación de los datos un nivel más detallado. Para validar filas en función de criterios más específicos se utiliza el componente tSchemaComplianceCheck. La mejor opción es la creación de un job que contiene además los componentes tLogRow y RowReject para detectar los casos anómalos.
Se orquestan los componentes mencionados como sigue y se selecciona el fichero de entrada del cual se quieren validar los datos.
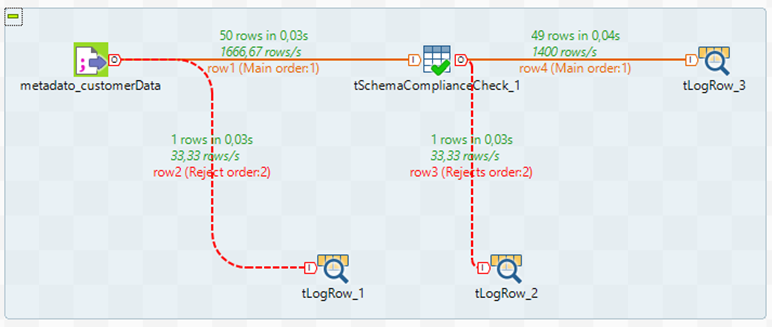
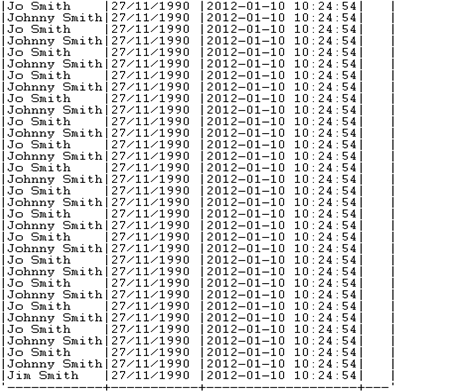
En este caso existen valores anómalos dentro de los valores del fichero de entrada:
· J Smith,27/11/1990,A,
· Johnny Smith asdlaskdjfaslkdffjasldkfjaskdfjlaksdfjl,27/11/1990,2012-01-10 10:24:54.953,
El propio componente detecta la estructura del fichero de entrada la cual es: name,dateOfBirth,timestamp,age
Como se puede observar, el primer valor anómalo contiene un valor alfanumérico para el campo timestamp y directamente dentro del componente tInputDelimited se rechaza como un valor que no cumple con los requisitos de formato del fichero de entrada, enviándolo a la salida tLogRow_1.
El segundo valor anómalo posee un nombre demasiado largo, por ello cuando el job establece la estructura del fichero, mediante el componente tSchemacomplianceCheck, este valor es rechazado debido a su gran tamaño y es mostrado como salida en el tLogRow_2.
La salida al ejecutar el job anterior es la siguiente:

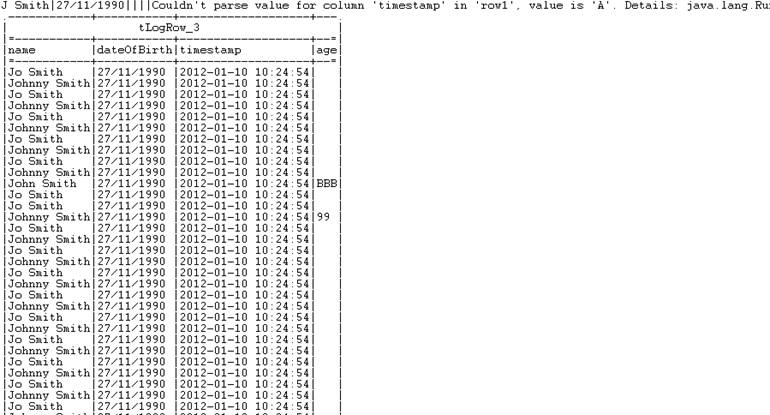


Como se puede observar, gracias a este job se ha conseguido no solo rechazar valores anómalos dentro del flujo, si no además identificar cuales son para así poder actuar sobre ellos como sea necesario.
Una alternativa al job “modelo a seguir” anterior para validar datos, es un job similar formado por el componente tMap que permite poder filtrar los datos en función de una expresión lógica.
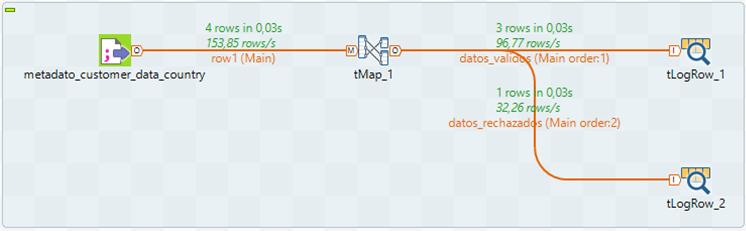
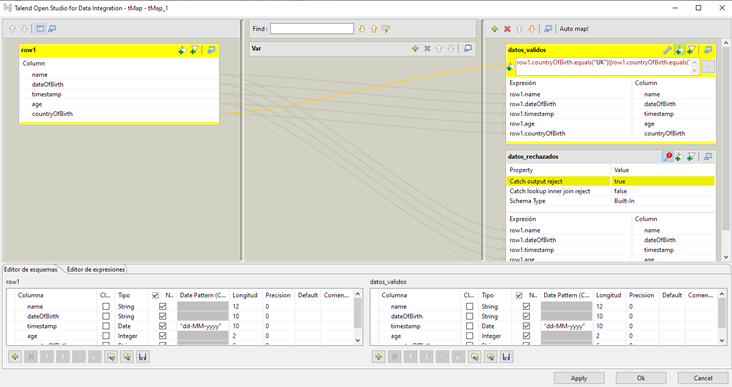
Solamente es necesario configurar el componente tMap con la expresión lógica correspondiente. En este caso se quieren filtrar aquellos registros cuyo campo CountryOfBirthsea igual a UK, FRANCE o USA.
El resultado de su ejecución es el siguiente.
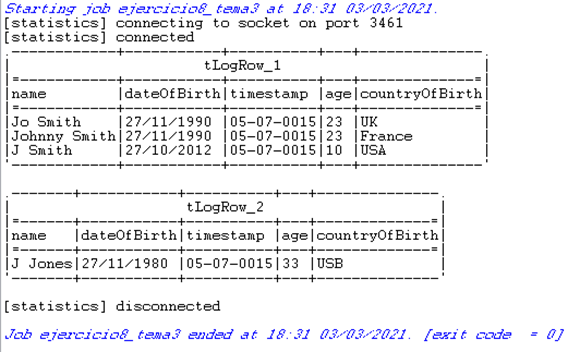
Con un funcionamiento similar al anterior se pueden filtrar los datos una vez se han validado.
Ahora el objetivo no es filtrar los registros con valores que cumplen con la estructura del modelo, si no filtrar aquellos registros que cumplen determinadas condiciones.
La manera más simple es mediante el componente tFilterRow, donde se establece una condición lógica para filtrar los registros, en este caso que la columna Currency será EUR.
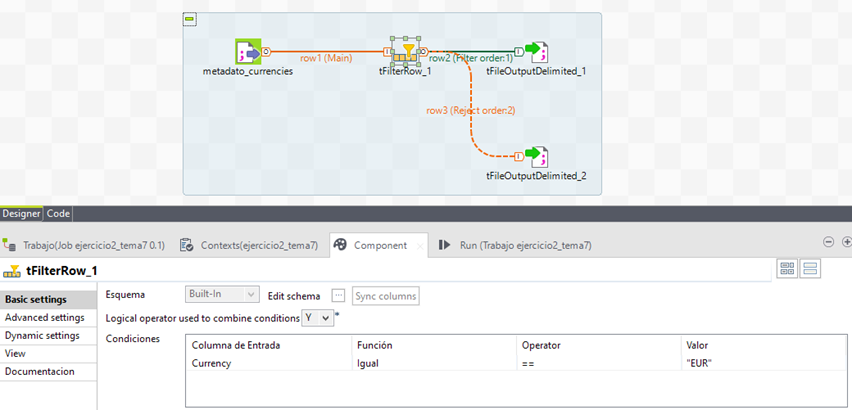
En un fichero se almacenarán los registros que cumplen con la condición y en otro el resto.
Orquestando los dos jobs generales que se han explicado en esta sección, se puede asegurar una correcta validación de los datos tanto a nivel estructural como a nivel registro (cumplimiento de condiciones lógicas).
2. Validación de un fichero antes de eliminarlo
Resumen: Presentar la importancia de la validación del fichero que se quiere eliminar dentro de un job.
Dificultad: 2
Utilidad: 4
Desarrollo: Un paso importante en cualquier job en el que se deseen eliminar ficheros, es validar si el fichero existe o no.Esta acción se realiza para vitar que el job provoque un error al leer por ejemplo un fichero que no existe.
Para ello, simplemente se debe de utilizar el componente tFileExist al inicio del job y una condición RunIf.
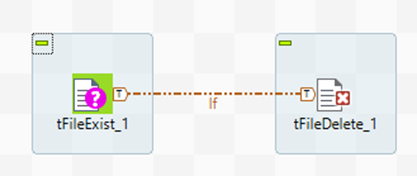
La condición If es: ((Boolean)globalMap.get("tFileExist_1_EXISTS"))
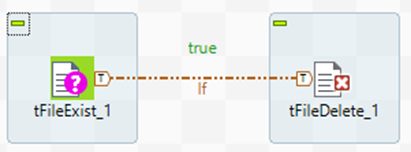
En la primera ejecución, la condición se evalúa como True debido a que el fichero existe, y entonces el job realiza su trabajo y lo borra.
En la segunda ejecución del job, como el fichero no existe, la condición se evalúa como false y el componente que elimina el fichero no se ejecuta y no provoca un error.
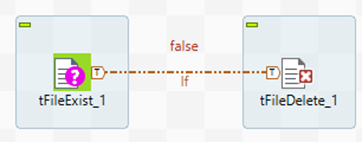
Es importante en la creación de jobs evitar los errores en ejecuciones, una manera de evitarlas es mediante este componente tFileExist.
3. TNormalize
Resumen: Este tip aborda la importancia de la normalización del dato en numerosos proyectos.
Dificultad: 1
Utilidad: 4
Desarrollo: A veces el conjunto de los datos no está normalizado, sin embargo, es una buena práctica trabajar con datos normalizados. El componente tNormalize permite realizar la normalización del dato de una manera muy sencilla.
Para realizar un ejemplo, se utiliza un fichero personal.csv que tiene el siguiente formato:
Departamento|Trabajadores
Ventas|Luis;Juan;Miguel
Compras|Sonia;Marina;Carlos
RRHH|María;Luisa
Los datos normalizados deberían de verse así:
Departamento|Trabajadores
Ventas|Luis
Ventas|Juan
Ventas|Miguel
Compras|Sonia
Compras|Marina
Compras|Carlos
RRHH|María
RRHH|Luisa
Para conseguirlo, se orquesta el siguiente job.
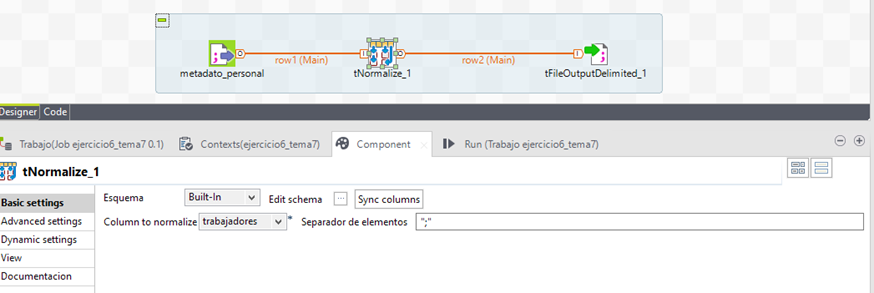
El job, importa los datos del fichero origen mencionado (con separador |), normaliza los datos (columna trabajadores) mediante el componente tNormalize y se exportan finalmente en otro fichero csv de salida.
Gracias a este componente, desde TOS se puede trabajar con datos normalizados que en el origen no lo estaban.
4. Business Model
Resumen: Este tip explica la creación de modelos de negocio desde Talend Open Studio.
Dificultad: 1
Utilidad: 4
Desarrollo: Una de las funcionalidades de TOS es la creación de Business Models, también conocidos como diagramas o modelos de datos. Esta herramienta proporciona un lienzo en el que dibujar distintos modelos de negocio para que el usuario final pueda comprender el modelo empresarial.
Un Business Models se crea desde la pestaña Repositorio, Business Models -> click derecho Create Business Model. Se crea entonces un lienzo en el que se pueden añadir distintos componentes visuales desde la paleta para crear una vista de un modelo de negocio personalizado.
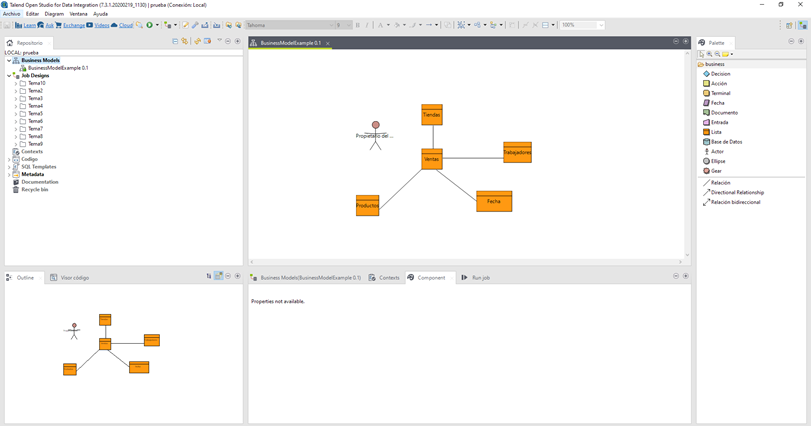
Gracias al uso de esta característica se pueden crear distintos tipos de diagramas con distintos niveles de detalle desde la propia herramienta de Talend sin tener que recurrir a herramienta externas.
5. Generar documentación automática
Resumen: Esta sección tiene como objetivo mostrar como generar documentación de un job de manera automática.
Dificultad: 1
Utilidad: 4
Desarrollo: Desde un job en Talend Open Studio se puede generar documentación automática. Esta documentación proporciona una gran cantidad de información acerca del job.
Para generarla solamente se necesita hacer click con el botón derecho sobre el job objetivo y Generate Doc as HTML. Lo siguiente es establecer la ruta donde se creará la documentación comprimida. El contenido de estas carpetas es:
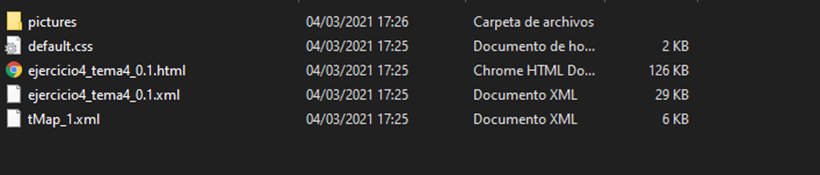
Una de las utilidades de esta funcionalidad es capturar la estructura visual del job y sus componentes sin recurrir a otras herramientas externas (peor calidad de captura). Desde la carpeta pictures se accede a diferentes imágenes con alta calidad del job general y sus componentes.
Sin embargo, la documentación se genera en formato HTML y se puede acceder a ella desde un navegador
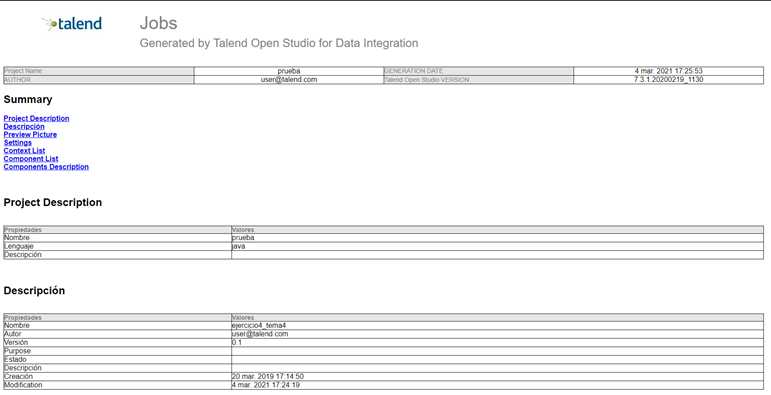
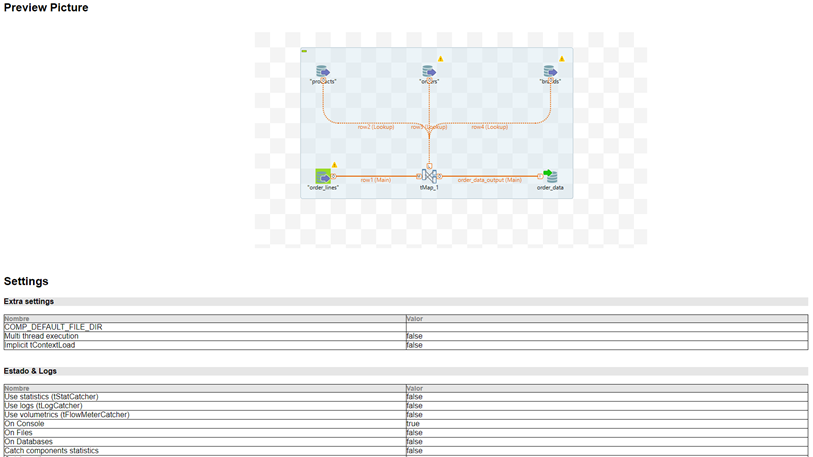
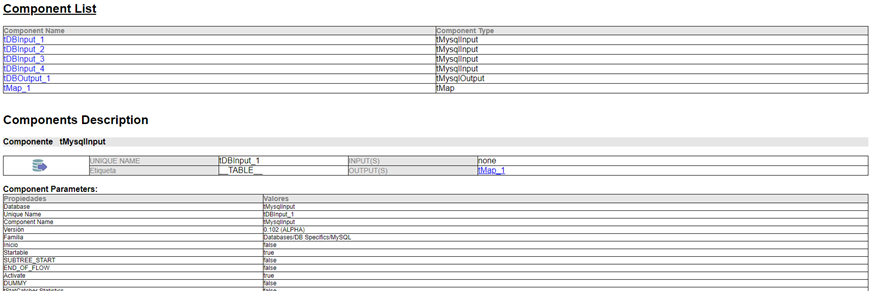
La documentación obtenida es muy completa y en ella se pueden encontrar distintas secciones como, por ejemplo, la configuración del job, los componentes que se utilizan y su respectiva configuración y descripción, las variables utilizadas, etc. Esta funcionalidad es muy útil a la hora de generar documentación cuando se está creando un job en TOS.
AVANZADOS
1. Registro de errores
Resumen: El propósito de este esta funcionalidad es explicar la utilidad del registro de los errores en la ejecución de un job en Talend.
Dificultad: 4
Utilidad: 4
Desarrollo: Crear en cada proyecto un registro de los errores en la ejecución de un trabajo de manera sistemática, para poder reconocer porque ha fallado su ejecución. Mediante un Log4j y un servidor de registros, que se activa desde el menú Archivo -> Edit Project properties -> Log4j, se puede mantener un registro de las ejecuciones fallidas de un job.
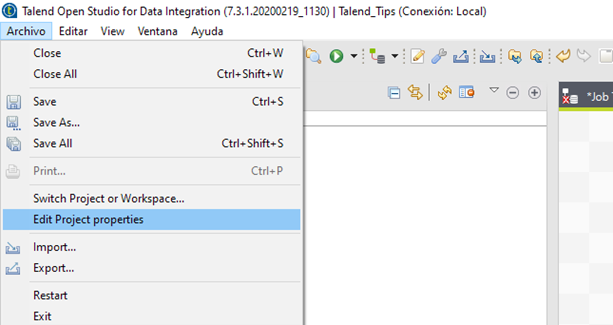
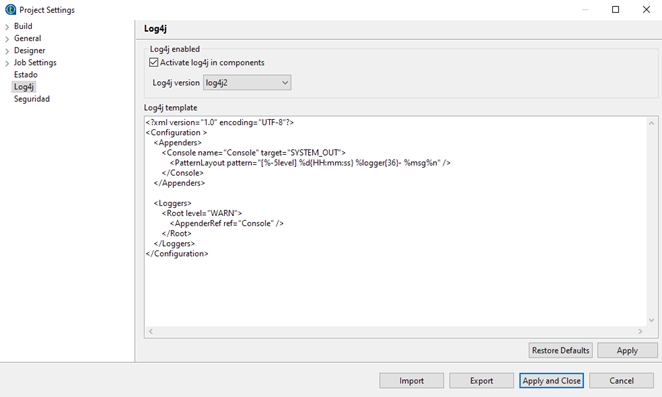
Para poder beneficiarse de esta funcionalidad desde Talend Administration Center se debe activar Log Stash.
2. Componentes personalizados
Resumen: El objetivo de esta sección es explicar como importar nuevos componentes a la paleta de Talend.
Dificultad: 3
Utilidad: 5
Desarrollo: Talend proporciona en su paleta, una cantidad de componentes muy amplia. Sin embargo, existe un mayor número de componentes gratuitos publicados en Talend Exchange que pueden ser útiles en numerosos escenarios. Para poder acceder a estos componentes, desde https://exchange.talend.com/ (es necesario estar registrado), se busca el componente que cumple con los requisitos o funcionalidad que se desea conseguir y se descarga.
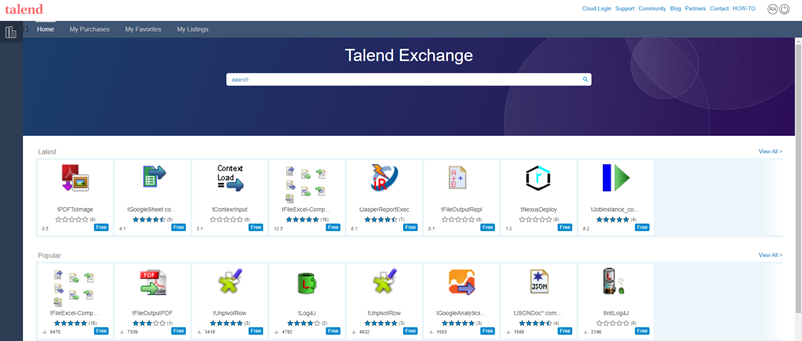
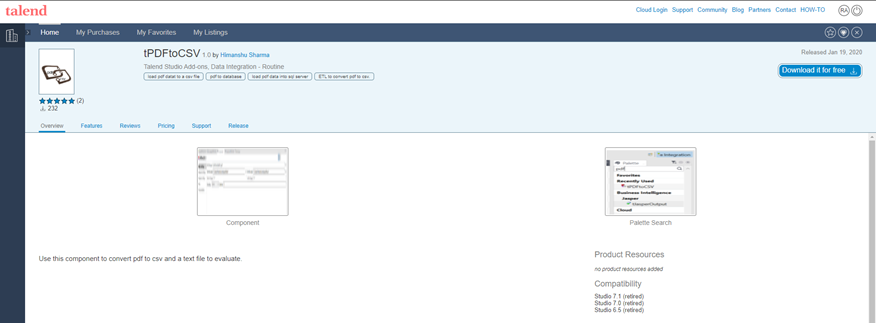
Se selecciona entonces desde TOS la opción Exchange. Después, Download extensions -> Install el componente descargado.
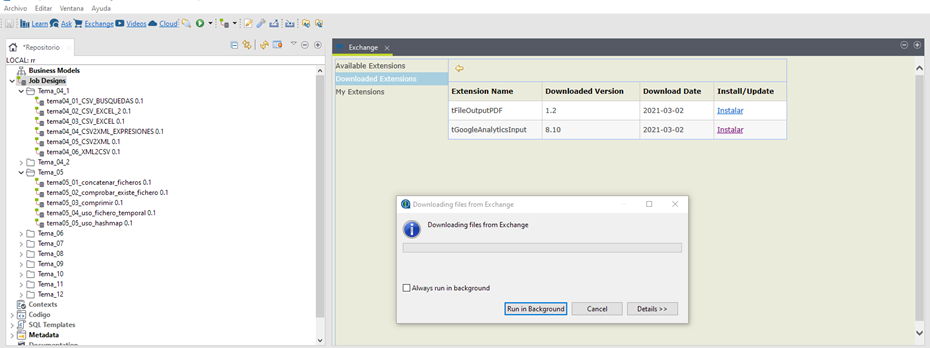
Después, el componente se mostrará como instalado y estará disponible en la paleta para utilizarlo en el job.
3. Generar documentación automática
Resumen: Esta sección especifica la utilidad de las rutinas en Talend.
Dificultad: 3
Utilidad: 4
Desarrollo:
Rutina: bloque de código Java.
Permite crear clases Java reutilizables.
Integración total con los trabajos creados.
Especial utilidad junto con el componente tMap o tJavaRow.
Ubicadas en el repositorio, en la sección Código -> Routines.
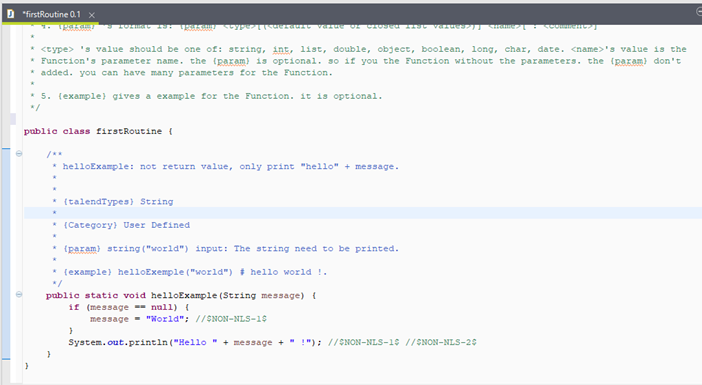
• Botón derecho sobre Routines y elegir la opción Create Routine.
• Introducir un nombre para la rutina y pulsar sobre Finalizar.
• Se abrirá una pestaña de código con una nueva clase usando el nombre introducido.
• Sobre este código se pueden efectuar las modificaciones deseadas.
• Después del método helloExampleintroducir el código contenido en el fichero tema9/rutina.txt
• Salvar los cambios y cerrar la pestaña de código.
• La rutina evalúa una entrada mediante el uso de expresiones regulares.
• El resultado es la sección de la cadena que cumple la expresión regular.
• Si no se encuentra coincidencia se devuelve null.
OTROS
1. Proyectos de referencia
https://www.talend.com/blog/2016/03/30/talend-job-design-patterns-best-practices-part-2/
2. Gestión de la memoria
Entonces, ¿quieres ejecutar tu trabajo? ¿Consideraste sus necesidades de memoria? ¿El flujo de datos está procesando millones de filas y / o tiene muchas columnas y / o muchas búsquedas en el tMap ? ¿Consideró cuando el trabajo se ejecuta en el ' Servidor de trabajos ' que otros trabajos podrían estar ejecutándose simultáneamente? ¿Pensó en cuántos núcleos / RAM tiene ' Job Server '? ¿Cómo configuró las combinaciones de tMap ? ' Cargar una vez ' o ' Fila por fila'? ¿Su trabajo llama trabajos secundarios o su trabajo es llamado por un trabajo principal, y cuántos niveles de trabajos anidados están involucrados? ¿Los trabajos secundarios se ejecutan en una JVM separada? Si escribe trabajos de ESB, ¿sabe cuántas rutas se están creando? ¿Está utilizando técnicas de paralelización (ver más abajo)? ¿Bien? ¿Consideraste estos? ¿Eh? Apuesto a que no ...
Los valores predeterminados están destinados a proporcionar valores base para los valores configurables. Los trabajos tienen varios, incluida la asignación de memoria. Pero los valores predeterminados no siempre son correctos, de hecho, es probable que estén equivocados. Su ' Diseño de trabajo de caso de uso ', su ' Ecosistema operativo ' y su ' Recuento de subprocesos de JVM en tiempo real ' determinan cuánta memoria se utiliza. Esto debe gestionarse.
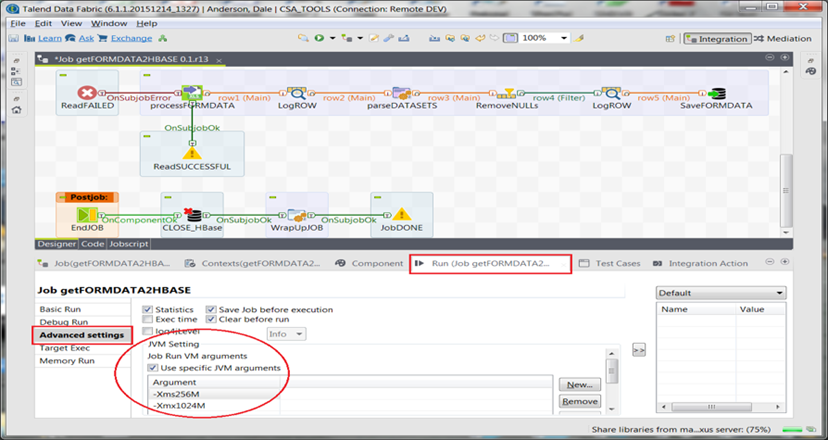
Puede especificar la configuración de la memoria JVM a nivel de proyecto o para trabajos específicos (como se indicó anteriormente):
Preferencias> Talend> Ejecutar
¡Haz esto bien o sufre el dolor! La gestión de la memoria a menudo se pasa por alto y como equipo, tanto desde el punto de vista del desarrollo como operativo, las directrices deben estar bien documentadas y seguidas.
3. Cargando contextos
Los ' grupos de contexto ' admiten un diseño de trabajos altamente reutilizable, pero todavía hay momentos en los que queremos aún más flexibilidad. Por ejemplo, suponga que desea mantener los valores predeterminados de las variables de contexto externamente. A veces, tenerlos almacenados en un archivo o incluso en una base de datos tiene más sentido. Tener la capacidad de mantener sus valores externamente puede resultar bastante efectivo e incluso respaldar algunas preocupaciones de seguridad. Aquí es donde entra en juego el componente tContextLoad.
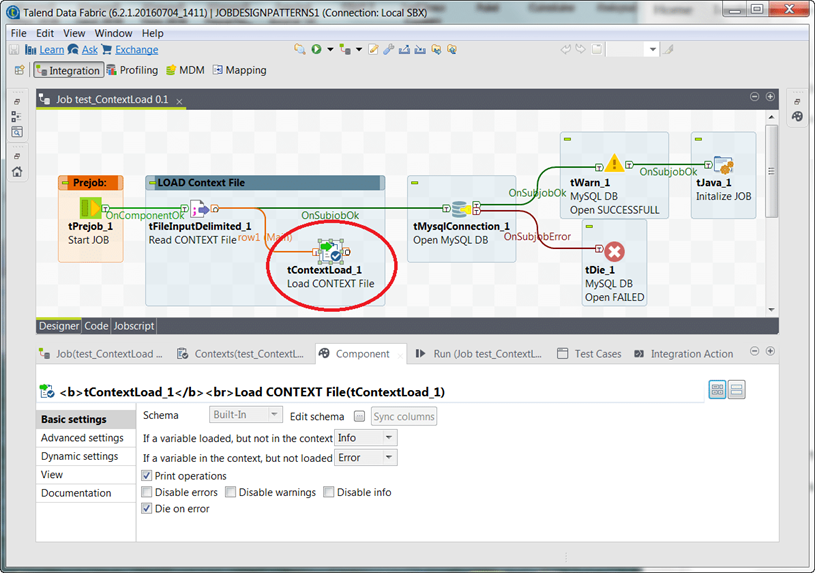
El ejemplo anterior muestra una forma sencilla de diseñar su trabajo para inicializar variables de contexto en tiempo de ejecución. El archivo externo que se usa para cargar contiene pares de nombres clave-valor delimitados por comas y, como se lee, anulará los valores actuales para las variables de contexto definidas dentro del trabajo. En este caso, los detalles de la conexión de la base de datos se cargan para garantizar la conexión deseada. Tenga en cuenta que tiene cierto control sobre el manejo de errores y, de hecho, esto presenta otro lugar donde un trabajo puede salir programáticamente de inmediato: ' Muere en caso de error '. Hay tan pocos de estos. Por supuesto, el componente tContextLoad puede usar una consulta de base de datos con la misma facilidad y conozco a varios clientes que hacen precisamente eso.
Hay un componente tContextDump correspondiente disponible, que escribirá los valores de la variable de contexto actual en un archivo o base de datos. Esto puede resultar útil a la hora de crear diseños de trabajo altamente adaptables.
4. Práctica recomendada n.° 3: uso de variables de contexto para consultas SQL generadas dinámicamente
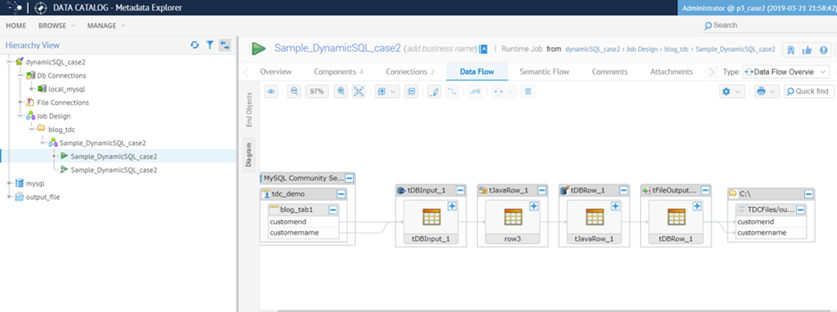
Que es una práctica muy común de hacer concatenaciones de cadenas, mientras que la formación de consultas SQL mediante programación. Talend DI J ob s tener en consideración dichos concatenaciones de cadenas en los componentes relacionados de SQL como tDBRow y componentes de código personalizado como tJavaRow . Dependiendo del componente donde se realiza la concatenación para formar una consulta SQL, esto podría crear dificultades para rastrear el linaje . La solución aquí es utilizar variables de contexto para la parte dinámica de la consulta SQL dentro de componentes SQL en lugar de código personalizado. Para entender mejor este escenario, utilice un trabajo de integración de Talend de ejemplo . Y él Job continuación es una sencilla Job con sólo una tDBInput componente utilizando una variable de contexto definido para el nombre de la tabla - se refiere a la imagen de abajo.
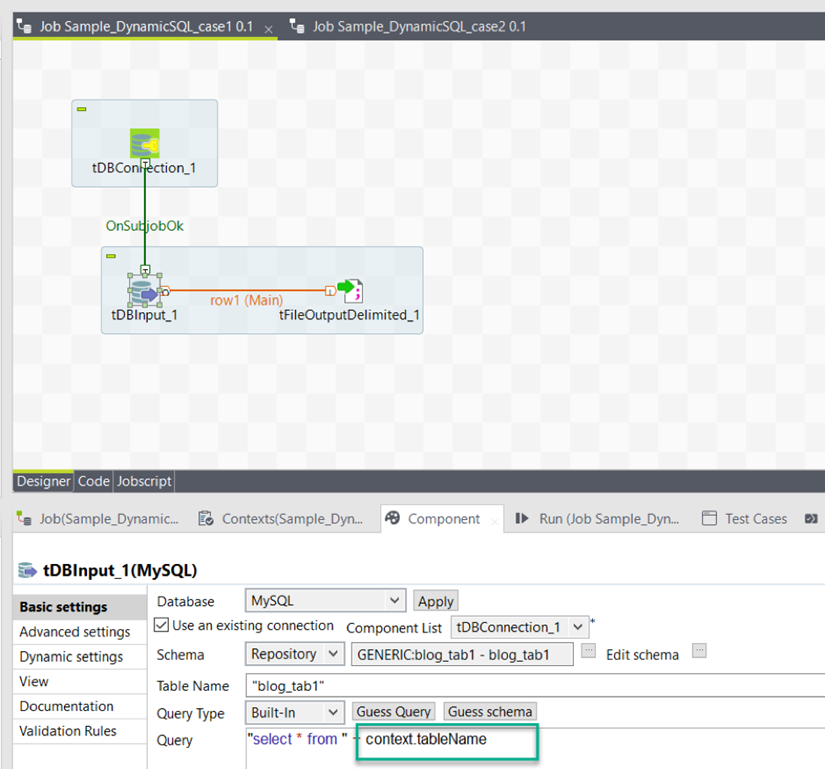
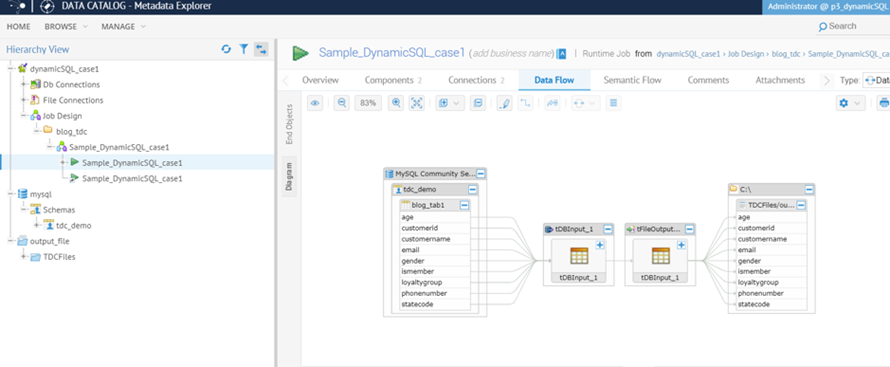
Y el linaje de datos funciona bien sin problemas.
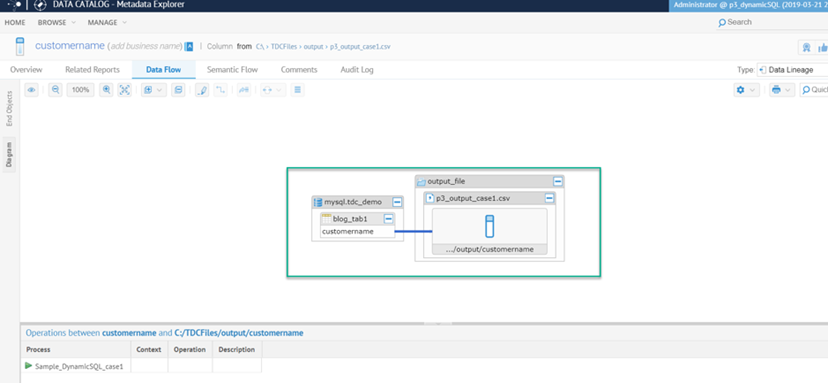
El segundo ejemplo de Job contiene un tJavaRow donde la consulta SQL se genera con concatenación de uso, consulte la imagen a continuación . Esto usa la misma variable de contexto para el nombre de la tabla que el primer Job.
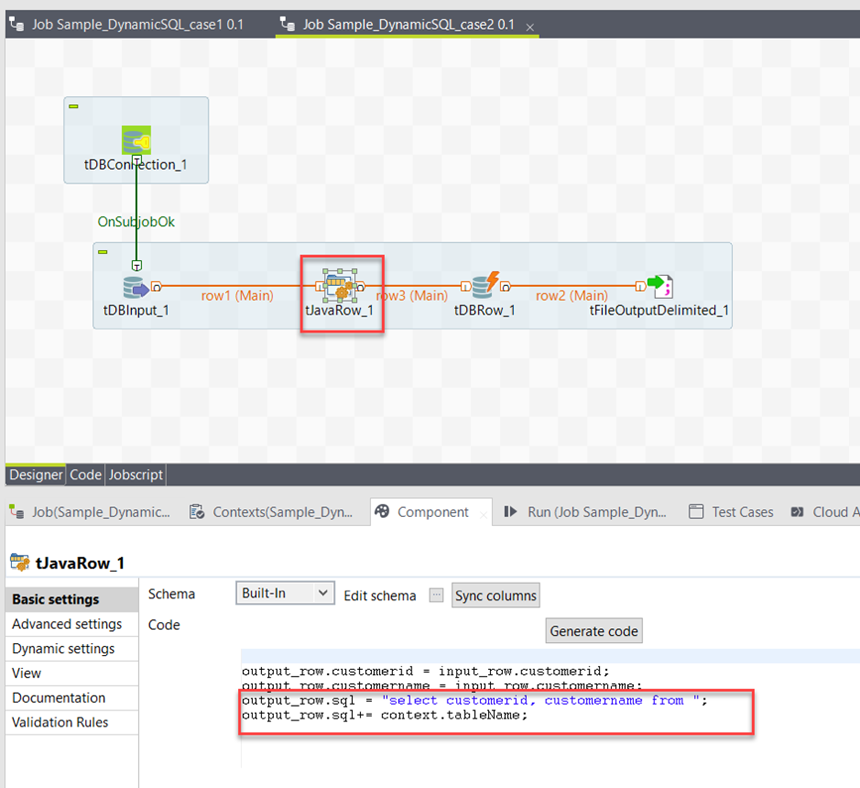
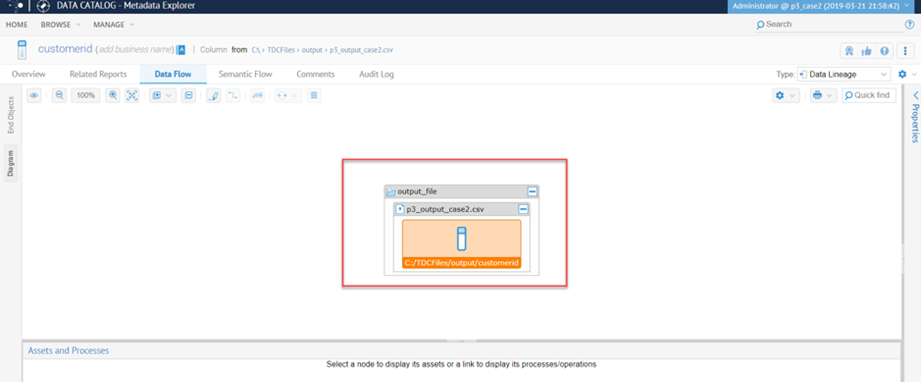
Con tDBRow que tiene la fila de salida ' sql ', esto se define para una consulta. Consulte la imagen a continuación:
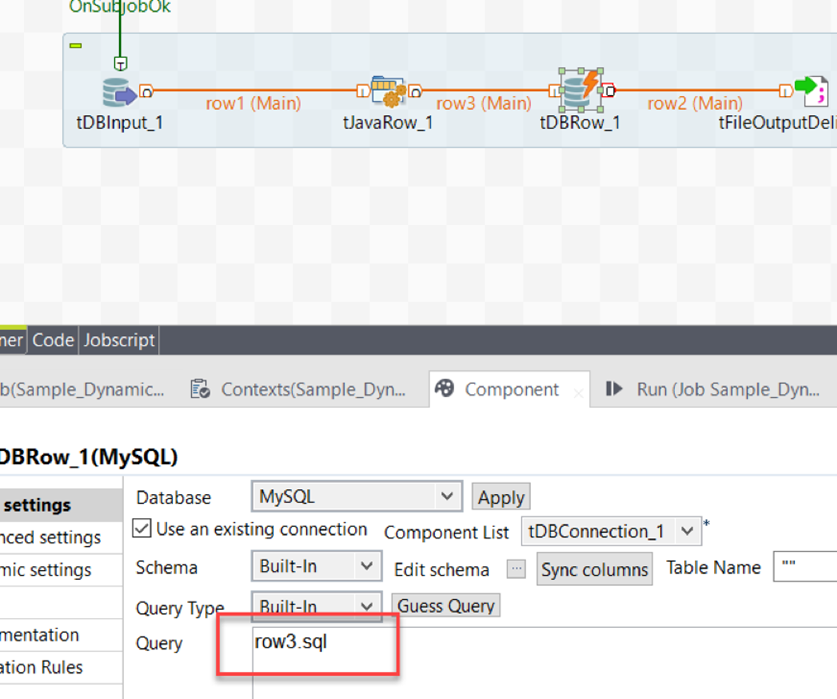
Aunque el flujo de datos muestra enlaces en todas partes, el linaje de datos se rompe. Consulte las imágenes a continuación: