🚀 Estas son las tecnologías que debes conocer al crear tu Moderna Arquitectura de Datos
🔎 Una 𝗠𝗼𝗱𝗲𝗿𝗻𝗮 𝗔𝗿𝗾𝘂𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗮 𝗱𝗲 𝗗𝗮𝘁𝗼𝘀 te debe proporcionar:
𝗢𝗿𝗾𝘂𝗲𝘀𝘁𝗮𝗰𝗶𝗼́𝗻 𝗲 𝗜𝗻𝘁𝗲𝗴𝗿𝗮𝗰𝗶𝗼́𝗻:Utiliza sistemas de orquestación y herramientas de integración de datos para facilitar la combinación y movimiento eficiente de información entre diversas fuentes y sistemas.
𝗘𝗹𝗮𝘀𝘁𝗶𝗰𝗶𝗱𝗮𝗱 𝘆 𝗘𝘀𝗰𝗮𝗹𝗮𝗯𝗶𝗹𝗶𝗱𝗮𝗱:Crea arquitecturas elásticas que pueden es
Leer más...
🚀 dbt, explicado!!
🛠 Gran herramienta Open Source para agilizar el proceso de transformación de datos promoviendo la reutilización y el uso de código altamente legible
𝗖𝗢𝗡𝗧𝗘𝗡𝗜𝗗𝗢:
✅ ¿QUÉ ES DBT?
✅ INFORMACION FUNCIONAL Y TÉCNICA
- ¿Cómo funciona dbt?-¿Cuáles son las principales características de dbt?
- dbt Core vs dbt Cloud
-
Leer más...
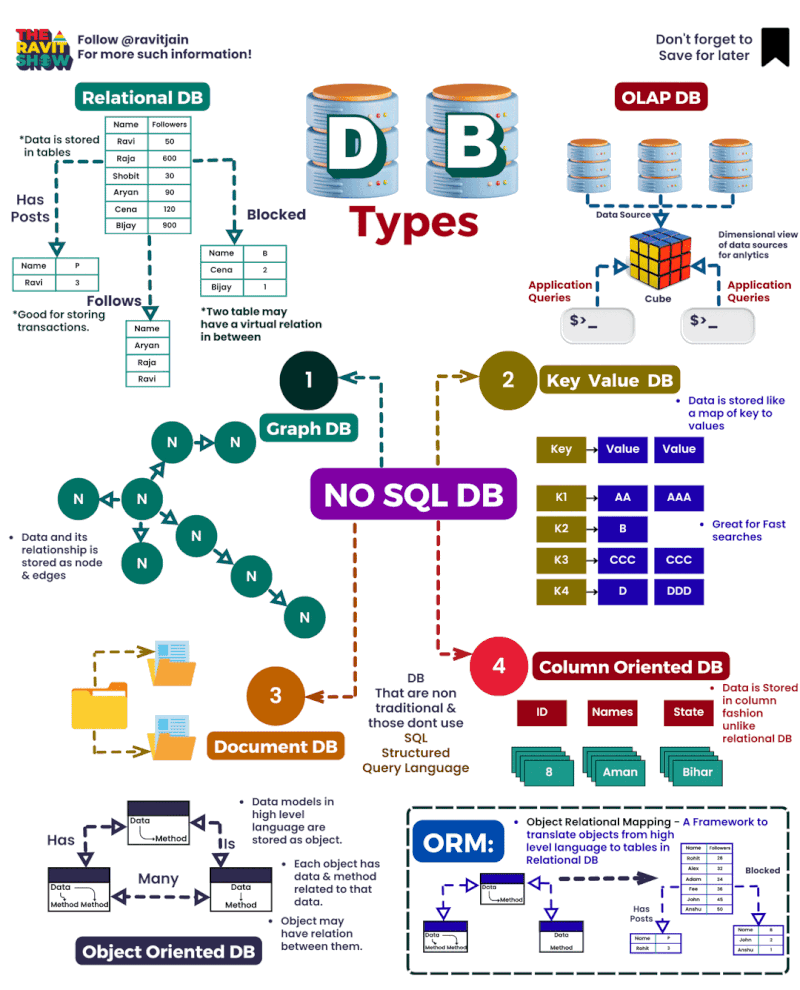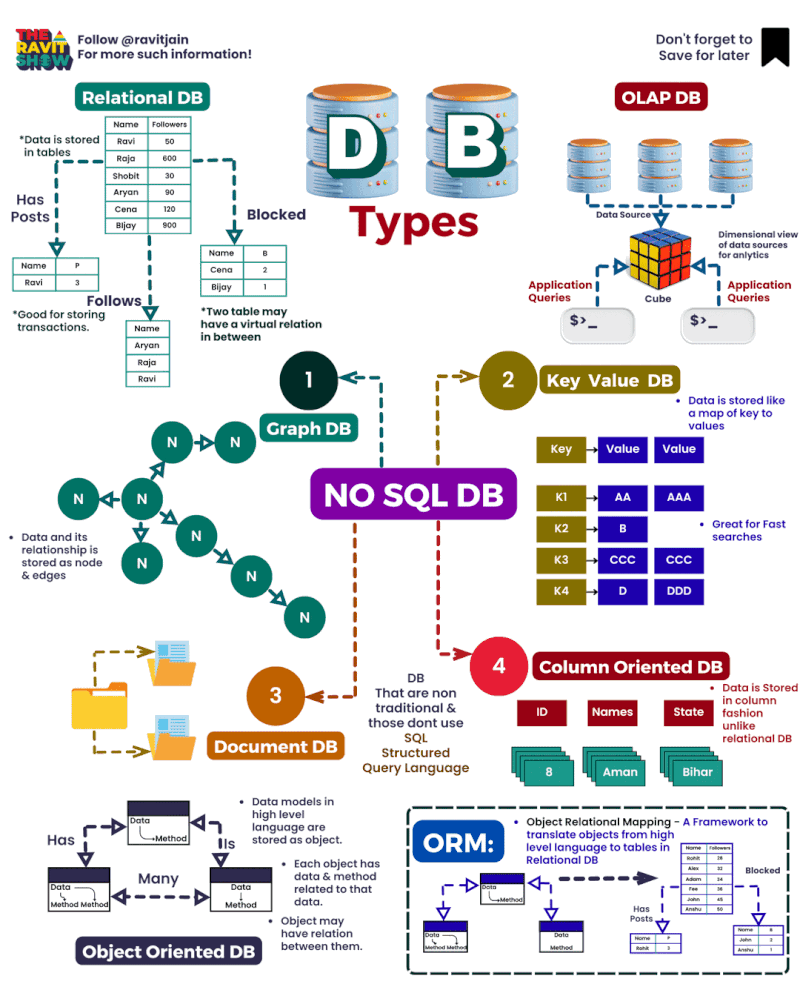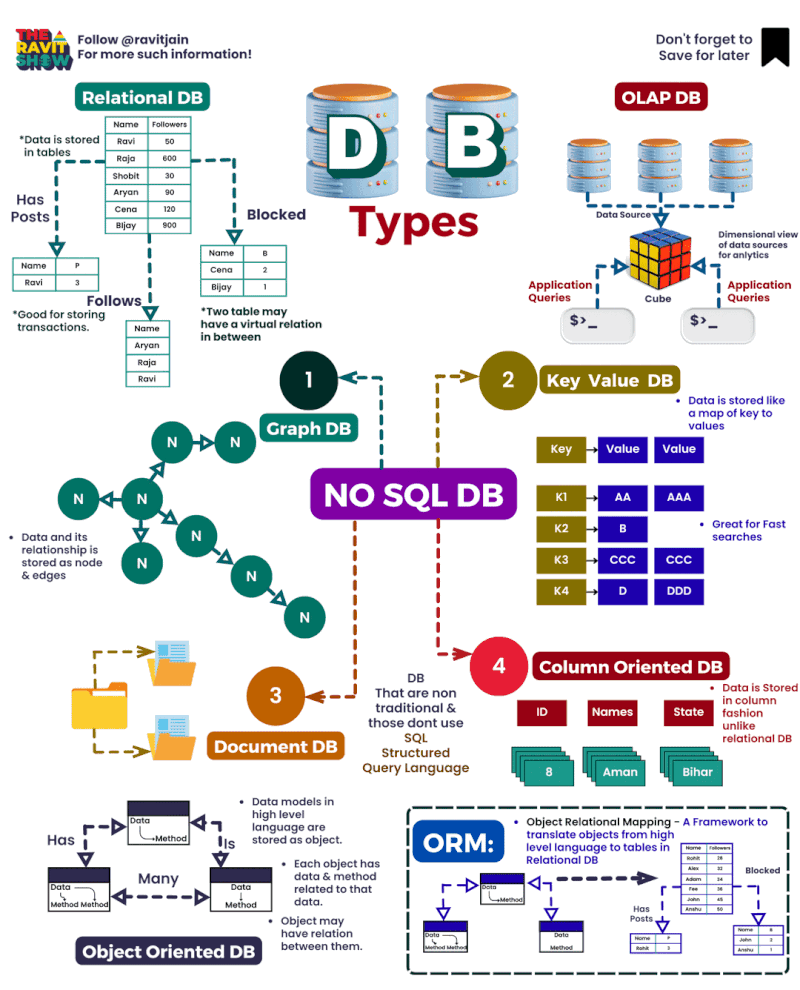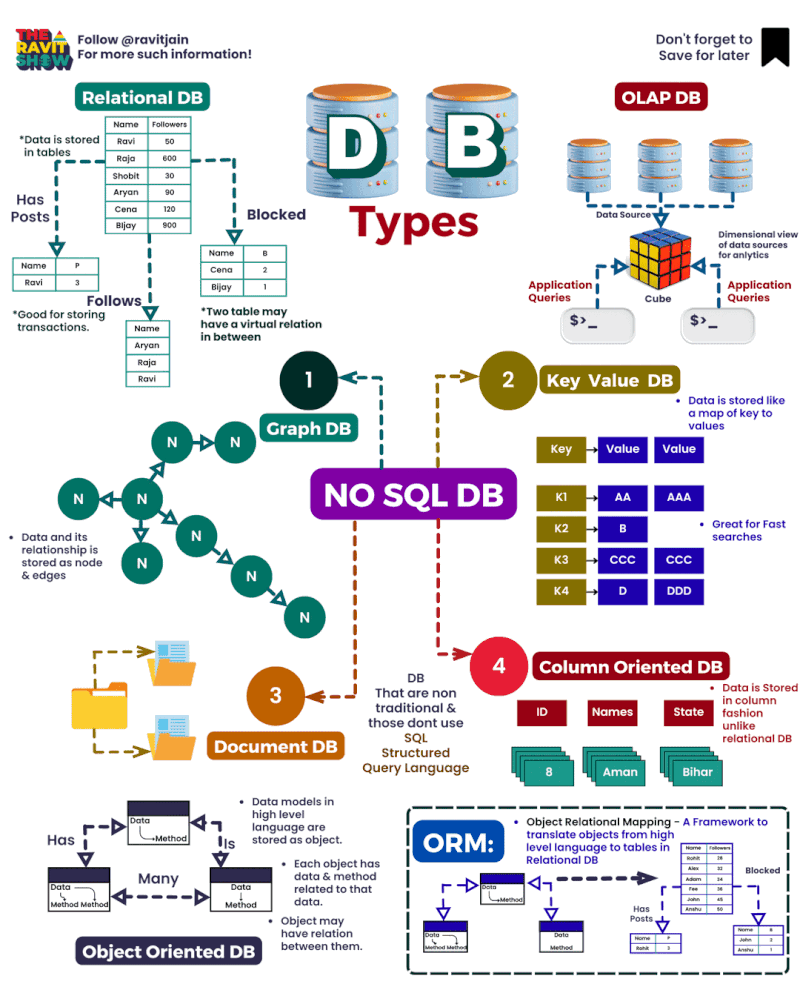
Here you have a compilation of the best diagrams to learn visually
PYTHON ROADMAP:
HOW A DATA ARCHITECTURE WORKS:
DATA SCIENCE LANDSCAPE:
HOW SPOTIFY USES MACHNE LEARNING:
WORKING OF A MACHINE LEARNING MODEL:
WHAT IS A VECTOR DATABASE:
PROMPT ENGINEERING HOW TO:
ML ENGINEER SKILLS:
DATA LINEAGE:
CLOUD WAREHOUSING:
DATA
Leer más...
💡 A todos os sonará #sparky #databricks, pero conoces qué hacen, sus diferencias, que es un #Lakehouse, un #DeltaLake, su Roadmap...
🚀 Pues hace unos días estuvimos en el LAKEHOUSE DAY en Madrid y os lo contamos, junto con las novedades para integrar ChatGPT, con Dolly
🙋♂️ En Stratebi somos especialistas en grandes
Leer más...
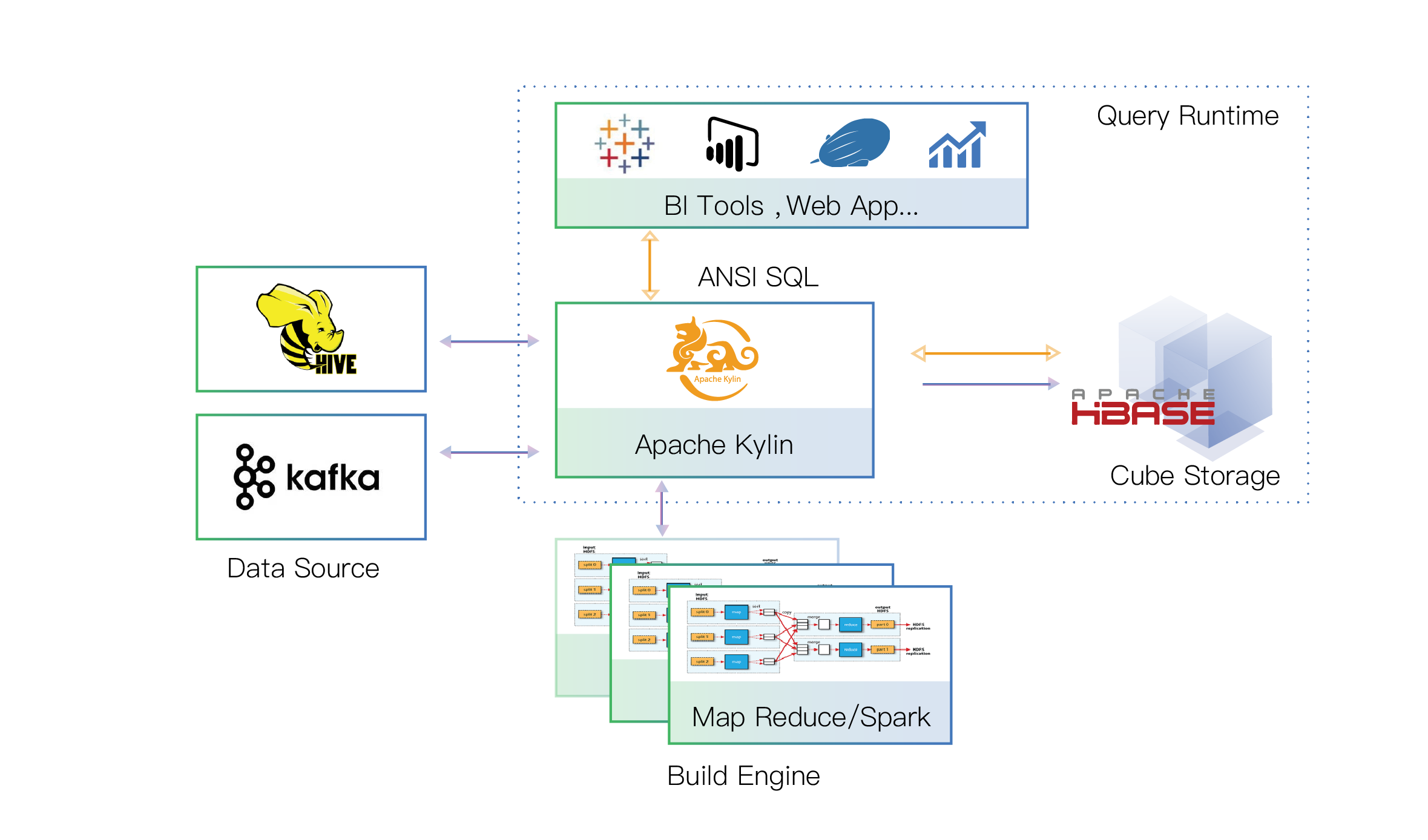
Muchos os hemos hablado por aquí de Apache Kylin [http://kylin.apache.org/],
probablemente el sistema de de consultas OLAP sobre Big Data más rápido y
potente del mercado. En la linea de Apache Druid, incluso con más
funcionalidades
Aquí os dejamos unos pocos enlaces:
Top real-time and best performance
Leer más...
One of the great technological challenges for all of us who are passionate about
Business Intelligence has always been to be able to meet three objectives that
seemed impossible:
1. Handling large volumes of data for analytical queries (olap,
multidimensional models).
2. To be able to do it in real-time
Leer más...
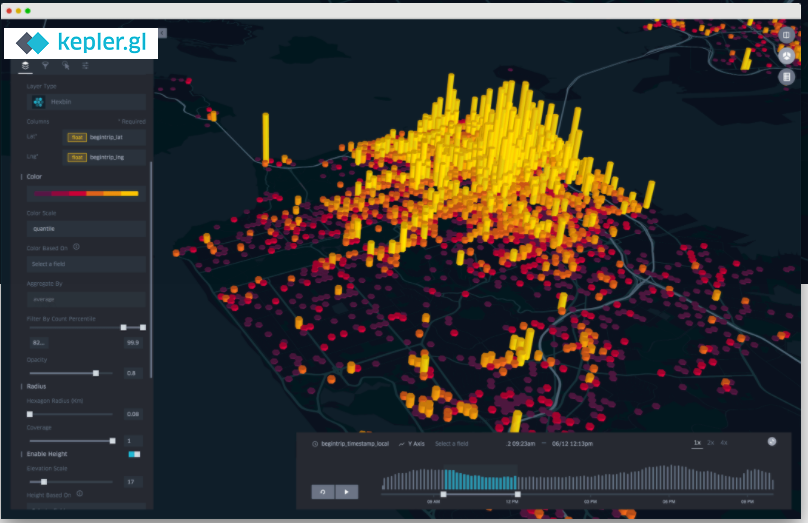
Kepler.gl [https://kepler.gl/] es una herramienta web de código abierto
desarrollada por Mapbox y Uber orientada a la visualización y análisis de datos
espaciales sobre mapas interactivos.
La herramienta permite construir fácilmente visualizaciones de datos sobre mapas
interactivos que pueden ser integrados en plataformas de terceros como CARTO,
Leer más...
Cada vez son más las iniciativas Smart City que se llevan a cabo, no solo en
España, en donde hay iniciativas pioneras, si no a lo largo de todo el globo
En este post, os hacemos un resumen de las principales tecnologías open source
que se usan en estos proyectos,
Leer más...
En el primer capitulo que ha creado nuestro compañero Emilio Arias
[https://www.linkedin.com/in/emilio-arias-9a26222/], tras el capitulo piloto de
introducción, nos habla sobre la muerte del Business Intelligence, que muchos
vienen contando en los últimos meses/años, tras la llegada de las herramientas
de Data Discovery, Cloud
Leer más...