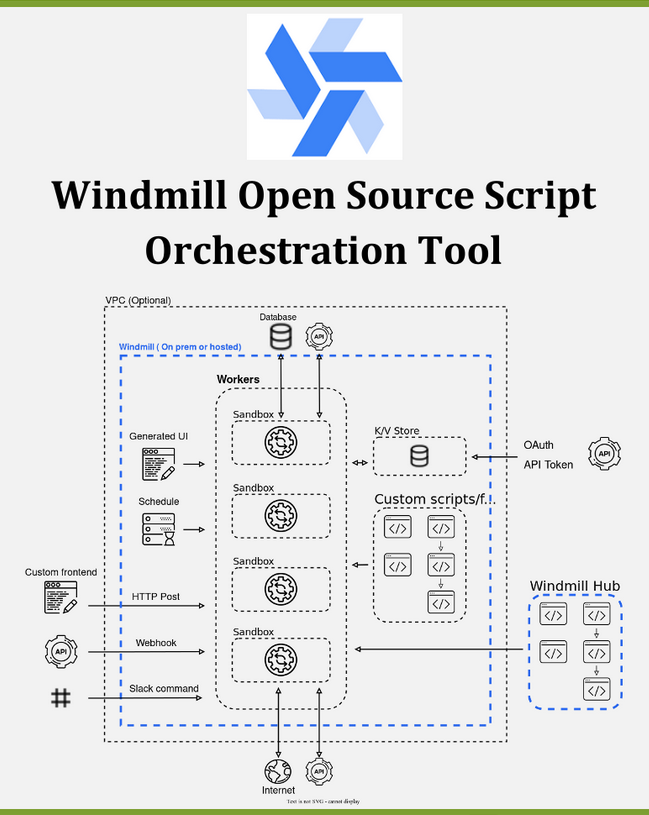
🚀 Esta es la nueva alternativa open source para orquestación de data pipelines que mejora a Apache Airflow en muchos puntos. Os cuento!!
🔎 Windmill es una herramienta de código abierto que permite la orquestación de scripts en diversos lenguajes como TypeScript, Go, Python, Bash...
𝗗𝗲𝘀𝗰𝗮𝗿𝗴𝗮𝗿: https://windmill.dev/
Descargar paper
✅ En adición
Leer más...
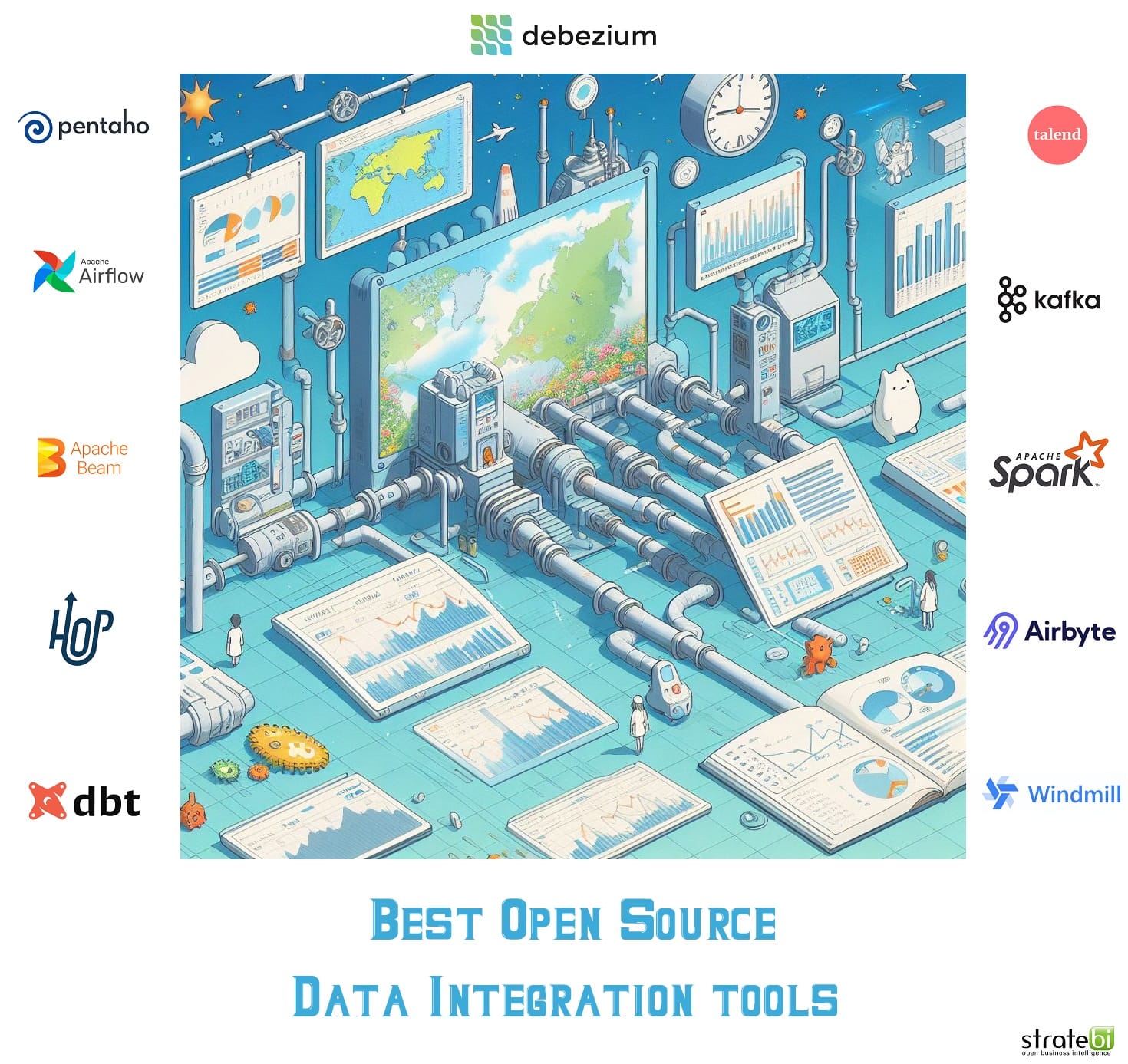
Estas son las mejores herramientas y tecnologías open source que nos permiten 'mover datos de un sitio a otro'
Os doy un poco de contexto sobre lo de 'mover datos de un sitio a otro':
* ETL: (Extract, Transform, Load)
* ELT: (Extract, Load, Transform)
* CDC (Change Data
Leer más...
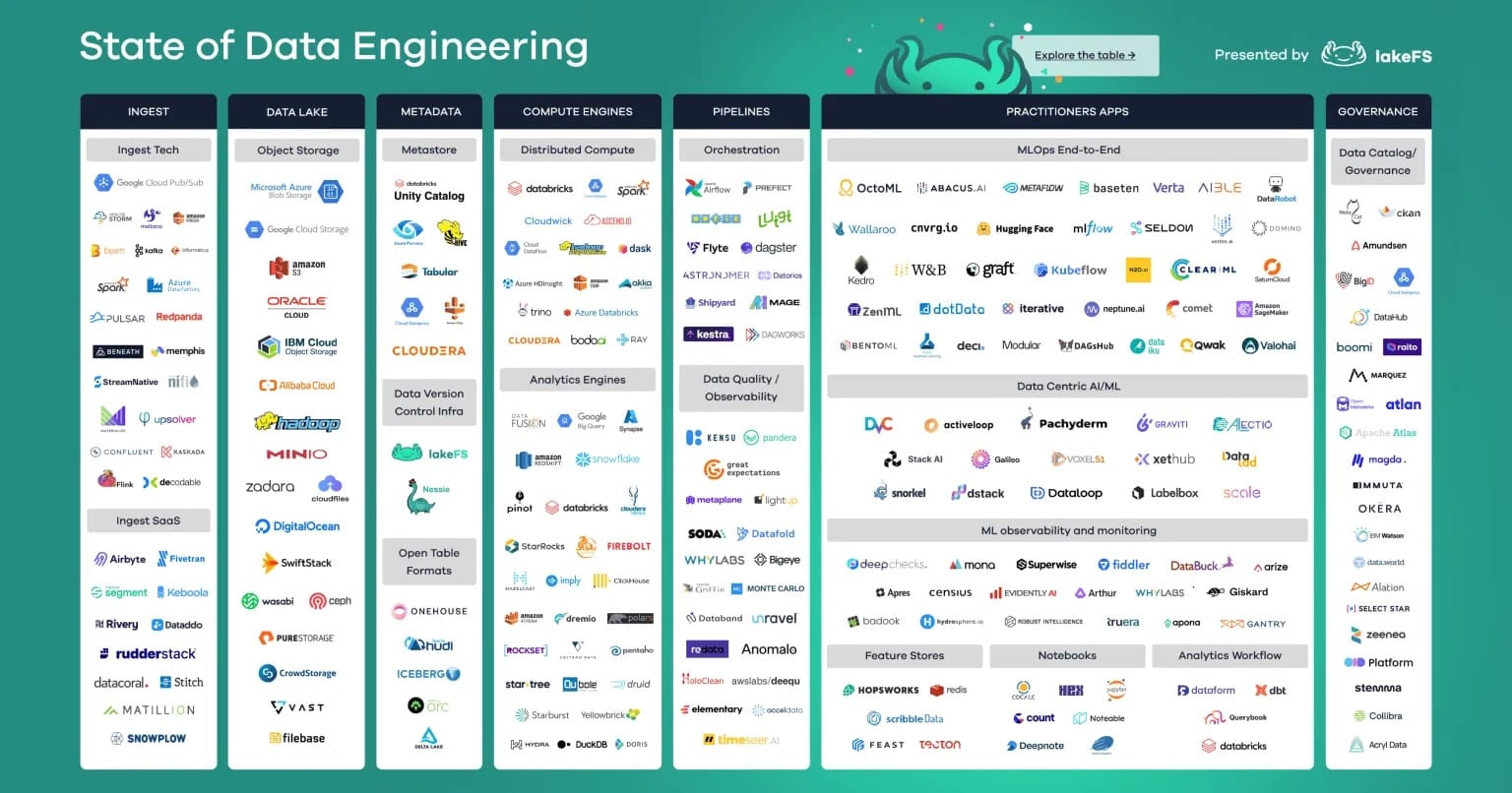
🚀 Si trabajas con Datos, esta recopilación de herramientas te vendrá genial!! Guardatela!! +100 herramientas!!
🔎 Algunas de las mencionadas en este documento, también las he venido comentando con más detalle aquí, en www.todobi.com
𝗧𝗜𝗣𝗢𝗦 𝗗𝗘 𝗛𝗘𝗥𝗥𝗔𝗠𝗜𝗘𝗡𝗧𝗔𝗦:
✅ Ingest Tech
✅ Ingest SaaS
✅ Data Lake
✅ Metastore
✅ Data Version
✅ Open Table Formats
✅ Distribute Compute
✅ Analytics Engine
Leer más...
🚀 Genial el 'Practical Data Engineering Project' que se acaba de actualizar en GithubUna gran forma de aprender de manera práctica y con tecnologías que me encantan de las que ya os he venido contando recientemente!!
🔽 Descargar de Github: https://lnkd.in/dmiy7igX
✅ En este proyecto de Ingeniería de
Leer más...
Here you have a compilation of the best diagrams to learn visually
PYTHON ROADMAP:
HOW A DATA ARCHITECTURE WORKS:
DATA SCIENCE LANDSCAPE:
HOW SPOTIFY USES MACHNE LEARNING:
WORKING OF A MACHINE LEARNING MODEL:
WHAT IS A VECTOR DATABASE:
PROMPT ENGINEERING HOW TO:
ML ENGINEER SKILLS:
DATA LINEAGE:
CLOUD WAREHOUSING:
DATA
Leer más...
💡 A todos os sonará #sparky #databricks, pero conoces qué hacen, sus diferencias, que es un #Lakehouse, un #DeltaLake, su Roadmap...
🚀 Pues hace unos días estuvimos en el LAKEHOUSE DAY en Madrid y os lo contamos, junto con las novedades para integrar ChatGPT, con Dolly
🙋♂️ En Stratebi somos especialistas en grandes
Leer más...
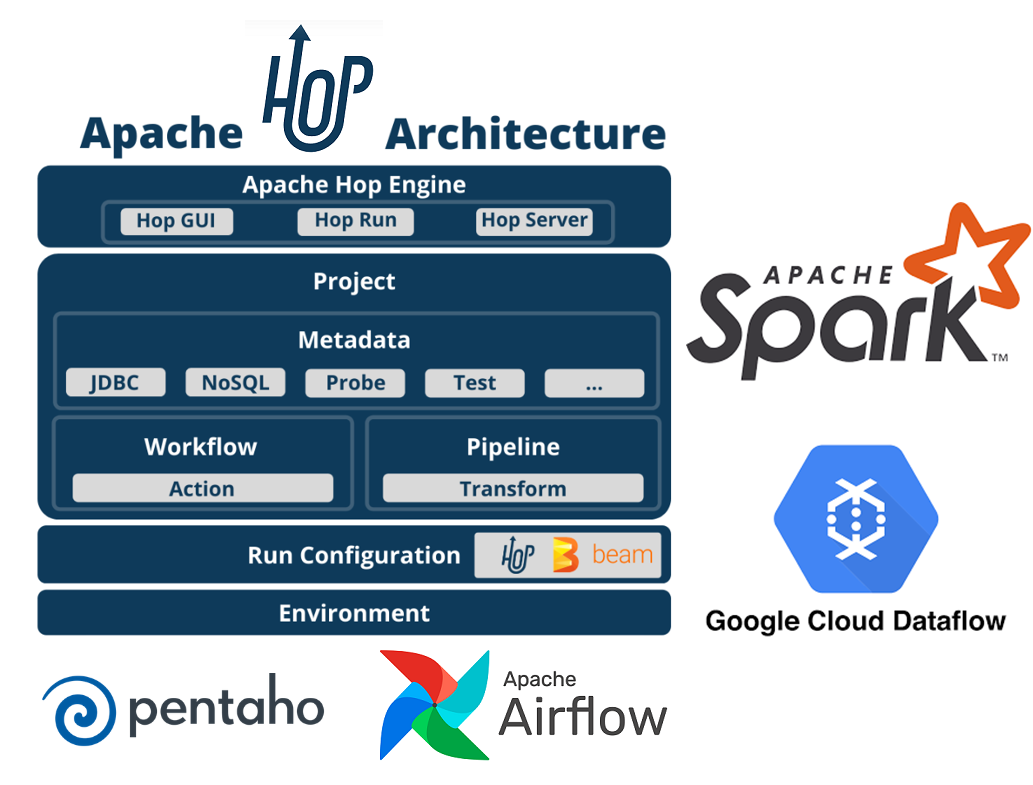
⚙ Apache Hop es la evolución de Pentaho (Pentaho Data Integration) y trae algunas mejoras notables 🚀 en cuanto a la integración con otras tecnologías Big Data (Spark, Airflow, Google Cloud Dataflow...)
Cualquiera que esté familiarizado con PDI no tendrá problema alguno en comenzar con Apache Hop. Y si no lo conoces,
Leer más...
🔔🔔 Hemos organizado un Curso práctico online sobre las mejores herramientas Open Source Analytics . Ya lo podéis ver de forma gratuita. Son casi 4 horas muy bien aprovechadas!!
🎬 Acceso al Curso: https://lnkd.in/dkxSjc4u
'Curso práctico completo sobre las mejores 15 herramientas Open Source Analytics'
Os será de
Leer más...
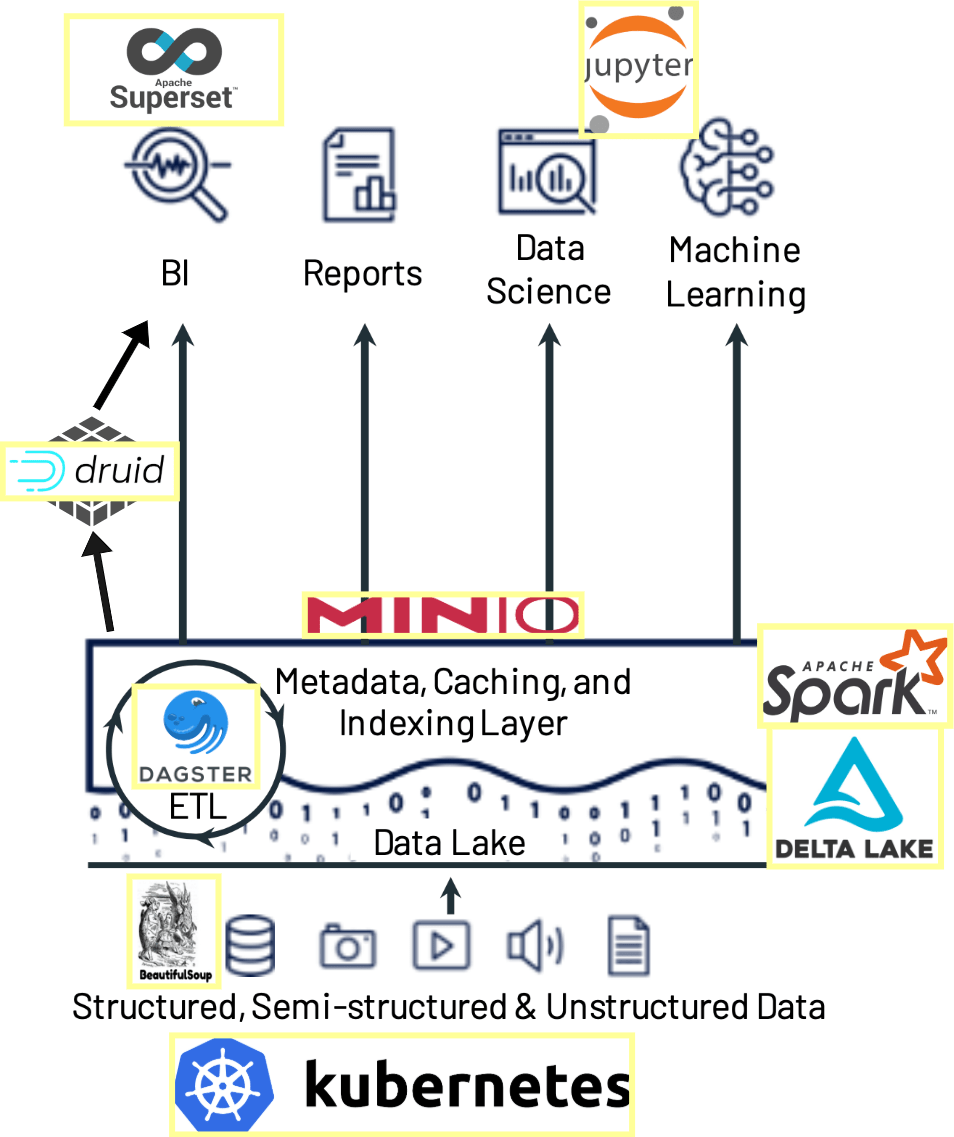
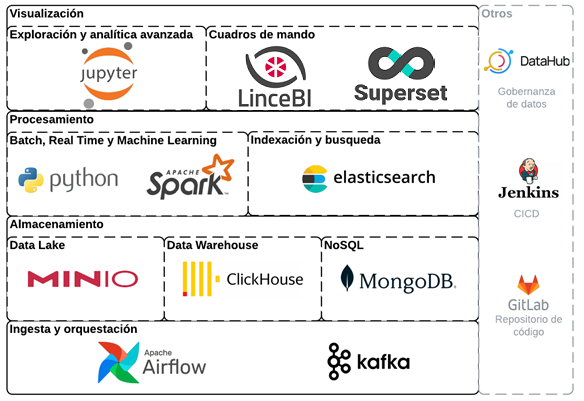
Cuando queremos definir la Arquitectura tecnológica de un Data Lake, éste debe
permitir la ingesta, integración, almacenamiento y explotación de cualquier tipo
de fuentes de datos
Apostamos por el uso de software libre, pero para el que exista un importante
soporte de la comunidad de usuarios que facilite su uso
Leer más...