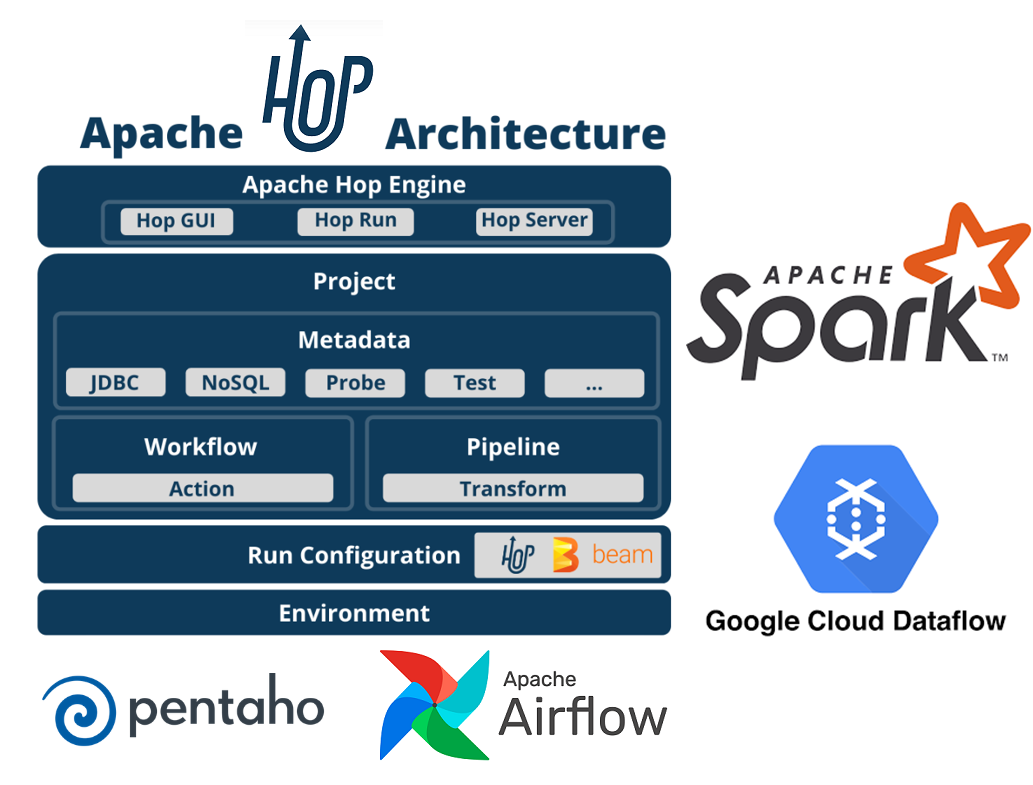
⚙ Apache Hop es la evolución de Pentaho (Pentaho Data Integration) y trae algunas mejoras notables 🚀 en cuanto a la integración con otras tecnologías Big Data (Spark, Airflow, Google Cloud Dataflow...)
Cualquiera que esté familiarizado con PDI no tendrá problema alguno en comenzar con Apache Hop. Y si no lo conoces, es el momento.
Además, es #opensource
Aquí tenéis detalle de como trabajar con Apache Hop. Además, tengo la suerte de conocer a sus creadores: Matt Casters y Bart Maertens, muy buenos técnicos y buena gente
📗 1. INTRODUCCIÓN
- Referencias
- Descarga
📗 2. OVERVIEW DE APACHE HOP
- Transformaciones disponibleS
- Proyectos y environments
- JDBC drivers y otros plugins
- Control de versiones
- Kettle import
📗 3. MIGRACIÓN Y COMPARACIÓN CON PDI.
📗 4. EJECUCIÓN DE PIPELINES CON APACHE SPARK
- Arrancar Spark
- Configuración del pipeline runtime engine de Spark en Hop
- Ejecución del pipeline
📗 5. EJECUCION DE PIPELINES CON GOOGLE DATAFLOW
📗 6. PLANIFICACIÓN DE ETL
- Scheduling con Google Dataflow
- Scheduling con Apache Airflow
📗 7. LOGS Y HOP-RUN
📗 8. BUENAS PRACTICAS
- Naming
- Variables
- Gobernanza
📗 9. CONCLUSIONES
Apache Hop: Instalación y construcción de pipelines con Apache Spark y Google Dataflow