

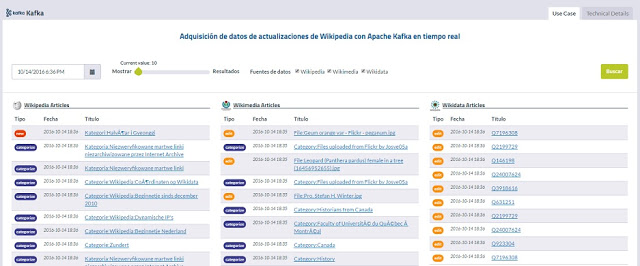
Este es un buen ejemplo de uso de Apache Kafka en entornos Big Data para consultas y visualización. Ver
Cuadro de Mando
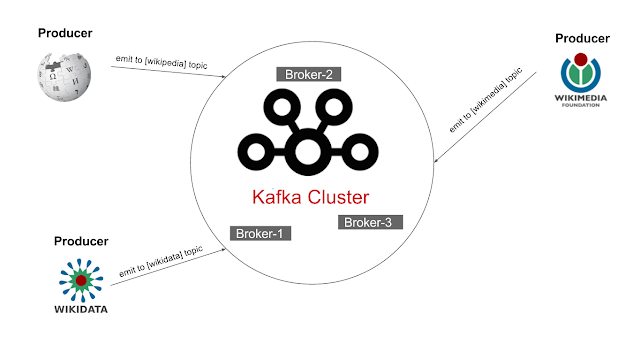
En la imagen inferior se muestra el cluster de
3
brokers
y
3 producers
que emiten datos hacia el
cluster kafka
.
El componente
"Kafka Producer"
se conecta al stream de la wikipedia y registra un
listener
, que es un sujeto del
patrón
observer
; cuando se genera una actualización en la wikipedia se recibe a través del "Socket" y este lo notifica al "Listener", que contiene un
org.apache.clients.producer.KafkaProducer
, el producer registra un
callback
para notificarle que se ha enviado un mensaje a kafka, la notificación contiene el
offset
y la
partición
de cada mensaje, en este paso se envía cada minuto vía
API
el tiempo en milisegundos y el offset para ese tiempo.
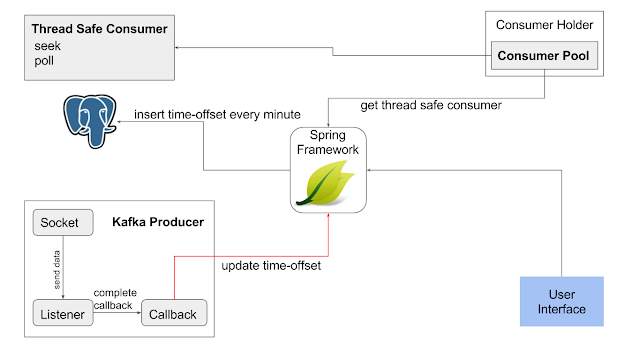
Esta información se almacena en una Base de Datos
PostgreSQL
, para luego ser consultada. Cuando el usuario selecciona una fecha a partir de la cual quieren ver los mensajes, el sistema busca en la Base de Datos un
offset
registrado en la fecha solicitada, el cluster kafka mantiene los mensajes en los ficheros locales por
3 días
.
Una vez obtenido el offset para la fecha requerida se solicita por medio del
"Consumer Holder"
un
"Thread Safe Kafka Consumer"
que realiza las operaciones
seek
y
poll
, para indicar el punto y consumir a partir de él respectivamente.
Pordefecto,un
org.apache.kafka.clients.consumer.KafkaConsumer
no es
Thread Safe
, por tanto para ser usado en un entorno con accesos simultáneo de usuarios se hizo una
implementación
que permite usar un Consumer por varios
hilos
,
sinchronizando
el acceso al objeto.