

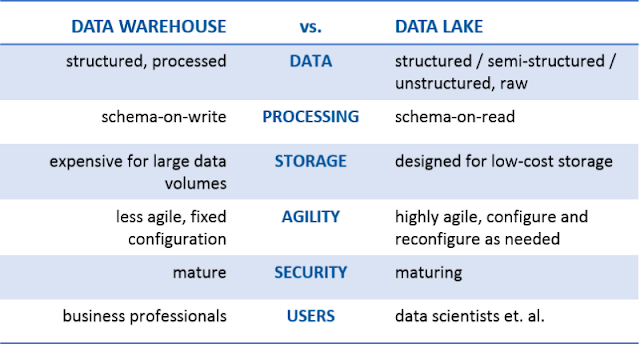
Let’s briefly take a look at each one:
- Data . A data warehouse only stores data that has been modeled/structured, while a data lake is no respecter of data. It stores it all—structured, semi-structured, and unstructured. [See my big data is not new graphic. The data warehouse can only store the orange data, while the data lake can store all the orange and blue data.]
- Processing . Before we can load data into a data warehouse, we first need to give it some shape and structure—i.e., we need to model it. That’s called schema-on-write. With a data lake, you just load in the raw data, as-is, and then when you’re ready to use the data, that’s when you give it shape and structure. That’s called schema-on-read. Two very different approaches.
- Storage . One of the primary features of big data technologies like Hadoop is that the cost of storing data is relatively low as compared to the data warehouse. There are two key reasons for this: First, Hadoop is open source software, so the licensing and community support is free. And second, Hadoop is designed to be installed on low-cost commodity hardware.
- Agility . A data warehouse is a highly-structured repository, by definition. It’s not technically hard to change the structure, but it can be very time-consuming given all the business processes that are tied to it. A data lake, on the other hand, lacks the structure of a data warehouse—which gives developers and data scientists the ability to easily configure and reconfigure their models, queries, and apps on-the-fly.
- Security . Data warehouse technologies have been around for decades, while big data technologies (the underpinnings of a data lake) are relatively new. Thus, the ability to secure data in a data warehouse is much more mature than securing data in a data lake. It should be noted, however, that there’s a significant effort being placed on security right now in the big data industry. It’s not a question of if, but when.
- Users . For a long time, the rally cry has been BI and analytics for everyone! We’ve built the data warehouse and invited “everyone” to come, but have they come? On average, 20-25% of them have. Is it the same cry for the data lake? Will we build the data lake and invite everyone to come? Not if you’re smart. Trust me, a data lake, at this point in its maturity, is best suited for the data scientists.
Visto en
kdnuggets