

Caso de estudio que presentamos, en el que hacemos uso de las herramientas Apache Kylin y STPivot para dar soporte al análisis interactivo OLAP de un almacén de datos (Data Warehouse, DW) que contiene datos con características Big Data (Volumen, Velocidad y Variedad)
Se trata de un gran Volumen de datos académicos, relativos a los últimos 15 años de una universidad de gran tamaño. A partir de esta fuente de datos, se ha diseñado un modelo multidimensional para el análisis del rendimiento académico. En él contamos con unos 100 millones de filas con medidas cómo los créditos relativos a asignaturas aprobadas, suspendidas o matriculadas. Estos hechos se analizan en base a distintas dimensiones o contextos de análisis, como el Sexo o la Calificación y la siempre presente componente temporal, el Año Académico.
Dado que este Volumen de datos es demasiado grande para analizarlo con un rendimiento aceptable con los sistemas OLAP (R-OLAP y M-OLAP) tradicionales, hemos decidido probar la tecnología Apache Kylin , la cual promete tiempos de respuesta en consultas de unos pocos segundos para Volúmenes superiores a los 10 billones de filas .
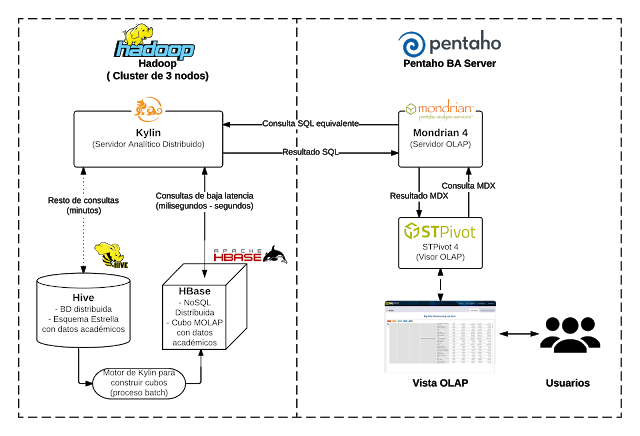
Las tecnologías del entorno Hadoop fundamentales para Kylin son Apache Hive y Apache HBase .
El almacén de datos (Data Warehouse, DW) se crea en forma de modelo estrella y se mantiene en Apache Hive.
A partir de este modelo y mediante la definición de un modelo de metadatos del cubo OLAP, Apache Kylin, mediante un proceso offline crea un cubo multidimensional (MOLAP) en HBase.
Ver Big Data-OLAP en funcionamiento
A partir de este momento, Kylin permite hacer consultas sobre el mismo a través de su interfaz SQL, también accesible a través de conectores J/ODBC.
Por último, para hacer posible el análisis OLAP mediante consultas MDX y las tablas o vistas multidimensionales correspondientes, hacemos uso de la herramienta STPivot.
STPivot es un visor OLAP desarrollado por StrateBI como parte de la suite STTools .
STPivot usa Mondrian como servidor OLAP y puede desplegarse sobre un servidor BI como Pentaho BA Server, ambos open source. De esta forma, STPivot permite crear y explorar vistas o tablas multidimensionales , cómo las de esta demo, que hacen uso del cubo OLAP creado con Apache Kylin .
Desarrollada por eBay y posteriormente liberada como proyecto Apache open source , Kylin es una herramienta de código libre que da soporte al procesamiento analítico en línea (OLAP) de grandes volúmenes de datos con las características del Big Data (Volumen, Velocidad y Variedad).
Sin embargo, hasta la llegada de Kylin, la tecnología OLAP estaba limitada a las bases de datos relacionales o, en el mejor de los casos, con optimizaciones para el almacenamiento multidimensional, tecnologías con importantes limitaciones para enfrentarse al Big Data.
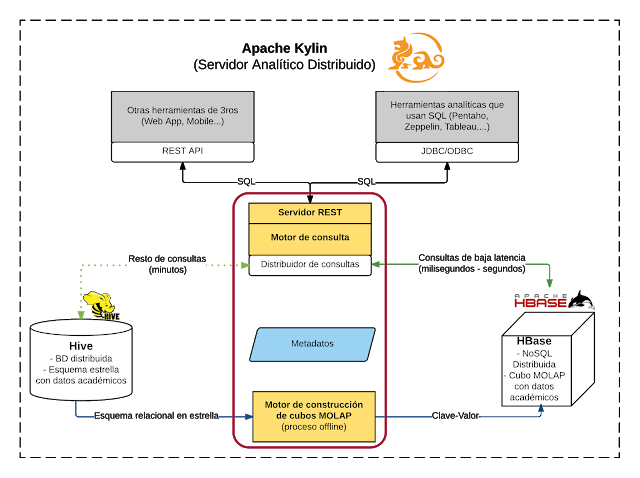
Apache Kylin, construida sobre la base de distintas tecnologías del entorno Hadoop , proporciona una interfaz SQL que permite la realización de consultas para el análisis multidimensional de un conjunto de datos, logrando unos tiempos de consulta muy bajos (segundos) para hechos de estudio que pueden llegar hasta los 10 billones de filas o más .
Las tecnologías del entorno Hadoop fundamentales para Kylin son Apache Hive y Apache HBase .
El almacén de datos (Data Warehouse, DW) se crea en forma de modelo estrella y se mantiene en Apache Hive. A partir de este modelo y mediante la definición de un modelo de metadatos del cubo OLAP, Apache Kylin, mediante un proceso offline, crea un cubo multidimensional (MOLAP) en HBase. Se trata de una estructura optimizada para su consulta a través de la interfaz SQL proporcionada por Kylin.
De esta forma cuando Kylin recibe una consulta SQL, debe decidir si puede responderla con el cubo MOLAP en HBase (en milisegundos o segundos), o sí por el contrario, no se ha incluido en el cubo MOLAP, y se ha ejecutar una consulta frente al esquema estrella en Apache Hive (minutos), lo cual es poco frecuente.
Por último, gracias al uso de SQL y la disponibilidad de drivers J/ODBC podemos conectar con herramientas de Business Intelligence como Tableau, Apache Zeppelin o incluso motores de consultas MDX como Pentaho Mondrian , permitiendo el análisis multidimensional en sus formas habituales: vistas o tablas multidimensionales, cuadros de mando o informes.
Ver Big Data-Dashboard en funcionamiento

STPivot es un visor OLAP potente a la par que fácil de usar , desarrollado por StrateBI y que forma parte de la suite de aplicaciones Business Intelligence, STTools .
El objetivo de este visor es mejorar la experiencia de usuario haciendo tan sencillo el análisis OLAP como arrastrar y soltar las medidas y contextos del análisis en un lienzo , de forma que la vista OLAP se genera de forma transparente al usuario.
Además, la incorporación de asistentes de consulta, gráficos novedosos además de las propias tablas multidimensionales, un editor de fórmulas avanzado o la exportación para la publicación de las vistas en distintos formatos, son algunas de las características más destacadas de STPivot y que diferencian nuestra herramienta de otros visores OLAP existentes.
En cuanto a su arquitectura, STPivot funciona sobre el motor de ejecución MDX, Mondrian .
Es por ello, qué STPivot puede usarse como aplicación del servidor de Business Intelligence open source Pentaho BA Server (CE) , el cual ya incluye Mondrian como parte del mismo.
Gracias a la conectividad JDBC es posible la conexión de Mondrian con Apache Kylin y, de esta forma, el uso de esta fuente de datos OLAP y Big Data con STPivot.
Como fuente datos Big Data de esta demo, disponemos de un gran Volumen de datos académicos ficticios , relativos a los últimos 15 años de una universidad de gran tamaño y por la que han pasado más de un millón de alumnos en este tiempo. A partir de esta fuente de datos, se ha diseñado un modelo multidimensional para el análisis del rendimiento académico
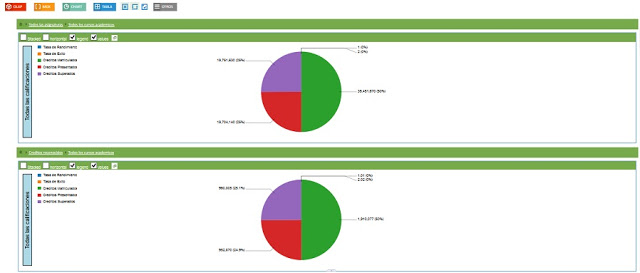
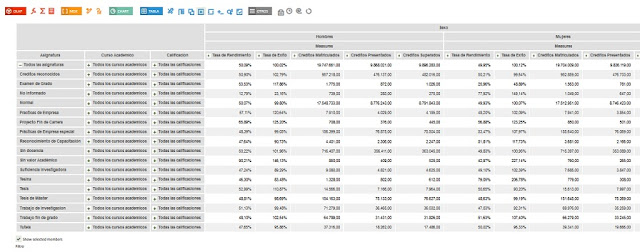
En él contamos con unos 100 millones de filas con medidas cómo la suma de los créditos relativos a asignaturas aprobadas, suspendidas o matriculadas.
Además también nos encontramos con otras medidas derivadas de las anteriores y, por tanto, más complejas como son la Tasa de rendimiento y Tasa de éxito, calculadas a partir de la relación entre Créditos Superados y Créditos Matriculados y de la relación entre Créditos Superados y Créditos Presentados.
No menos importantes son las dimensiones o contextos de análisis en base a los que se analizan las medidas anteriores. Como dimensiones de un solo nivel tenemos el Sexo, la Calificación, el Rango de Edad y la siempre presente componente temporal, el Año Académico. Además, hemos incorporado dos dimensiones complejas, con jerarquías de dos niveles y una mayor cardinalidad , siendo frecuente encontrarnos con dimensiones de esta naturaleza.
Con la dimensión Estudio, podemos analizar los datos agrupados al nivel de Tipo de Estudio (Grado, Máster, Doctorado,...) o profundizar (operación Drill Down sobre la vista OLAP) hasta los distintos Planes de Estudio, esto es, las distintas titulaciones, como "315-Grado en Biología".