

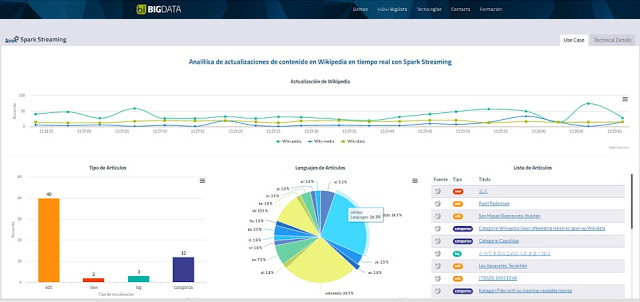
Al abrirse la página de esta demostración, se solicita una conexión con el
end point
que provee los datos de la wikipedia, mediante un
WebSocket
.
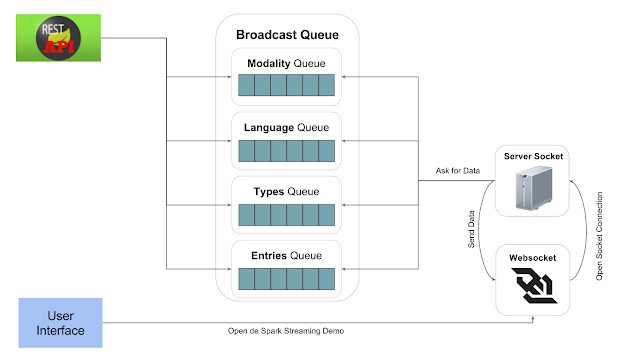
Enel servidor se crea una conexión con el cliente y mientras esté abierta y no ocurran errores en el envio, el sistema busca los datos de los componentes de
"Broadcast Queue"
. Estos componentes, a su vez, están recibiendo datos del
API REST
, que les llega a través del Cliente Http implementado y usado por
Spark
para enviar los resultados.
La implementación de la "Broadcast Queue", permite que todas las conexiones al servidor puedan buscar los datos en la misma cola obteniendo un
tiempo óptimo de O
(1), (
Complejidad Computacional
de obtener datos de una
Cola de Mensajes
) para cada conexión en recibir el mensaje.
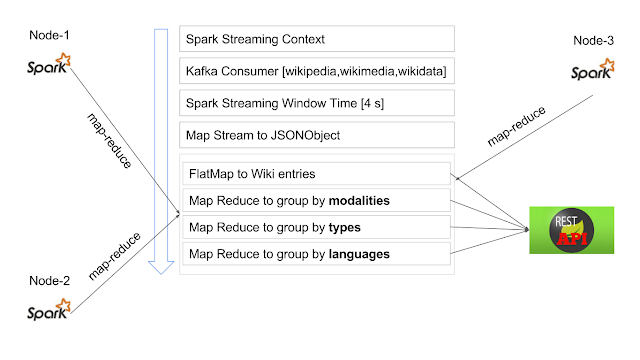
A su vez, en su papel de
Cola de Mensajes
permite que la comunicación entre Spark y el Server Socket sea óptima, en O(1) igualmente sin contar los
retrazos
por red.
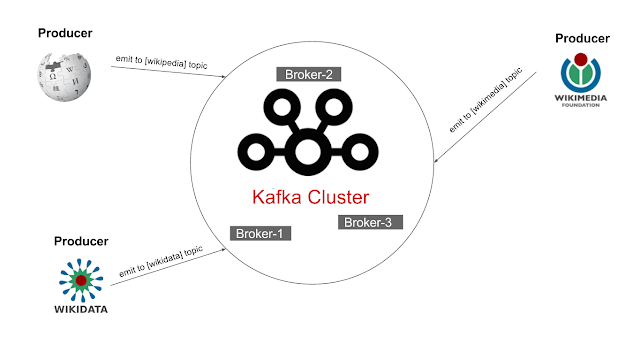
Esta implementación permite que un número muy
alto
de clientes puedan conectarse a visualizar en tiempo real los datos recibidos de la wikipedia.
Puedes ver también un video en funcionamiento:
Puedes ver también un video en funcionamiento: