Hace unos días se celebró en Madrid el evento
Elastic{ON}
tour, dónde los creadores y usuarios del conocido motor de búsqueda y analítica de datos, contaron las novedades sobre el mismo, así como algunos casos de uso en empresas como Orange o Banco Santander.

Shay Banon, creador de
Elastic
, abrió el evento con una presentación acerca del presente y futuro de Elastic. En primer lugar, puso de manifiesto que esta herramienta surgida como un motor de búsqueda en una base de datos de documentos (índice invertido), se ha convertido en un conjunto de herramientas mucho más potente,
ELK (Elasctiserach, Logstash y Kibana)
, dónde los usuarios además de implementar un sistema de búsquedas interactivos, tiene la posibilidad de implementar analítica de datos mediante la creación métricas de agregación (medias, recuentos, máximos, histogramas…), cuadros de mando y procesos de machine learning que se pueden crear de forma muy sencilla usando la herramienta Kibana.

Además, distintos miembros de elastic presentaron las novedades en algunas de las características más importantes y novedosas:
·
Data Rollups:
Pre agregación de datos de histórico mediante un asistente en Kibana, para mejorar el rendimiento de las consultas analíticas.
·
Canvas
:
Para la creación de cuadros de mando pixel-perfect con Kibana, mucho más personalizables que los que actualmente podemos desarrollar. Además, se mostró un ejemplo usando el módulo de Elastic que permite consultar datos con
lenguaje SQL
, en lugar de usar la sintaxis clásica de la API JSON de elascticsearch.
·
Machine Learning:
Se hizo hincapié en las características para la detección de outliers y generación de predicciones, características muy útiles por ejemplo para la detección de fallos o sobrecargas en infraestructuras.
·
Elastic Common Schema:
Esquema para el mapeo de campos comunes (ej. campos geográficos, como la ciudad)

No menos importantes fueron los casos de uso mostrados por Orange y Banco Santander.
En el caso de Orange, usan Elastic para varios objetivos como la monitorización de las infraestructuras (redes móviles, tv) o el análisis de los datos de llamadas (CDR).
En el caso del Banco Santander, lo están usando para proporcionar una plataforma de análisis financiero a través de su nube privada, como servicio de valor añadido a los inversores. En ambos casos se trata arquitecturas dónde se ha desplegado Elastic en clústeres que van de 10 a cientos de nodos.
Además, destaca la presencia de otros componentes de datos como
Kafka
, cola de mensajes distribuida que facilita el movimiento de datos en tiempo real a distintas partes de la Big Data pipeline y aumenta la tolerancia a fallos actuando como un buffer persistente.
Por todo ello, consideremos que Elastic es una herramienta consolidada para la implementación de búsquedas y analítica sobre logs u otros conjuntos de datos con características Big Data.
No obstante, en cuanto a la analítica de datos, existen algunas limitaciones frente a planteamientos tradicionales de Data Warehousing, como la imposibilidad de hacer joins entre tablas (índices o tipos de documentos en elasctic) y otras limitaciones en la forma de agregar los datos o la creación de métricas.
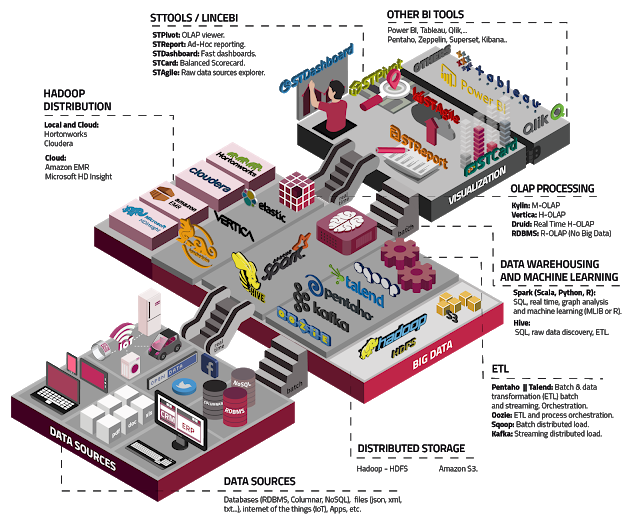
Por ellos es importante determinar si nuestro escenario de Big Data Analytics puede ser cubierto usando únicamente Elastic (ELK). No obstante, dado que la integración con entornos Hadoop es posible (ej. a través de Spark), podemos combinar lo bueno de ambos mundos para el procesamiento analítico del Big Data, como así proponemos en nuestro
Big Data Stack
.