

What is a data lake?
A
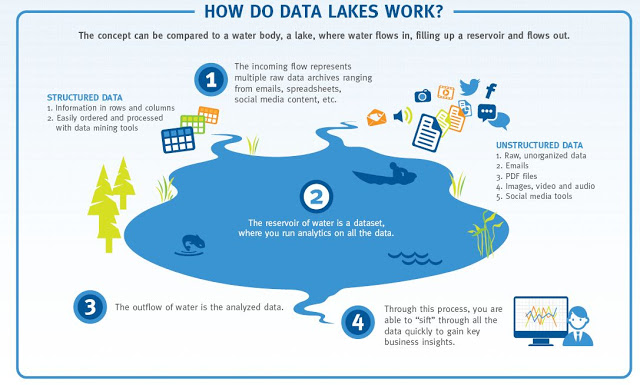
data lake
is a repository designed to store large amounts of data in native form. This data can be structured, semi-structured or unstructured, and include tables, text files, system logs, and more.
The term was coined
by James Dixon, CTO of Pentaho
, a business intelligence software company, and was meant to evoke a large reservoir into which vast amounts of data can be poured. Business users of all kinds can dip into the data lake and get the type of information they need for their application. The concept has gained in popularity with the explosion of machine data and rapidly decreasing cost of storage.
There are key differences between data lakes and the data warehouses that have been traditionally used for data analysis. First, data warehouses are designed for structured data. Related to this is the fact that data lakes do not impose a schema to the data when it is written – or ingested. Rather, the schema is applied when the data is read – or pulled – from the data lake, thus supporting multiple use cases on the same data. Lastly, data lakes have grown in popularity with the rise of data scientists,
who tend to work in more of an ad hoc, experimental fashion than the business analysts of yore.
{kind=link}