

Os hemos venido contando bastante de Vertica en TodoBI y no nos cansamos de recomendar esta espectacular Base de Datos analítica
Hoy os traemos algunos trucos para sacarle todo el partido en la ejecución de queries para conseguir el mejor rendimiento:
1. Transacciones
Al igual que otras tecnologías de bases de datos compatibles con ACID (Atomicidad, Consistencia, Aislamiento y Durabilidad), Vertica define las transacciones, que implican una o más sentencias SQL como una única unidad de trabajo. Al final de una transacción, las sentencias pueden ser confirmadas, es decir, aplicadas a la base de datos, o devueltas, en las que se deshacen los cambios de la base de datos. A diferencia de la mayoría de las tecnologías de bases de datos
Una vez que Vertica ha escrito los datos en los archivos del disco, no se vuelven a escribir. Como resultado, no hay contención entre las lecturas y las escrituras del disco y elimina la necesidad de registros indebidos.
2. Ejecución de querys
Se envía una consulta a uno de los nodos utilizando SQL estándar. Este nodo se llama el "Iniciador". Debido a que todos los nodos son iguales, cualquier nodo puede ser el "Iniciador". El componente Optimizador genera y examina los planes de consulta. Estos planes pasan por todas las proyecciones que son aplicables a la consulta y dictan cómo se ejecutará la consulta. El optimizador elige el plan de consulta que tiene el menor costo.
El nodo "Iniciador" distribuye un plan de consulta seleccionado a los otros nodos del grupo, llamados "Ejecutores". El "Iniciador" y los "Ejecutores" ejecutan el plan localmente en el subconjunto de datos contenidos en su nodo, así es como Vertica implementa el procesamiento masivo en paralelo. Los resultados de la consulta en cada nodo ascienden al nodo "Iniciador", que agrega todos los resultados. El resultado de la consulta se devuelve al remitente.
3. Épocas
Una época es una unidad lógica de tiempo en la que se hace un solo cambio en los datos del sistema. Esta unidad está representada por un número de 64 bits. Con cada confirmación, el número de época aumenta y los siguientes datos añadidos a Vertica se imprimen con la época actual. Las épocas se utilizan en Vertica para establecer puntos en el tiempo que permitan realizar consultas históricas, un punto a través de los nodos al que se puede reajustar una base de datos y un punto en el que los datos marcados con vectores de eliminación pueden ser eliminados permanentemente de la base de datos. Vertica admite los siguientes tipos de época:
La Época Actual (CE), es aquella en la que se están escribiendo los datos. Contiene todos los cambios no comprometidos.
La Última Época (LE), es el punto en el que se completó el compromiso de la base de datos más reciente.
La Última Buena Época (LGE), representa la época más reciente a la que la base de datos puede retroceder en caso de fallo de la base de datos. Este es el último punto en el que la base de datos funcionaba en todos los nodos.
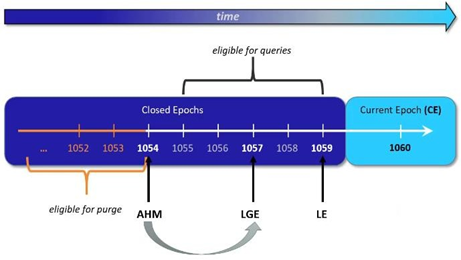
La Marca de Historia Antigua (AHM), marca el punto en el tiempo en el que los datos marcados para su eliminación pueden ser purgados de la base de datos. Las épocas que ocurren más tarde en la época de la AHM, pueden ser usadas en las consultas. Sus datos no pueden ser purgados físicamente. No se puede realizar una consulta histórica en una época más lejana que el marcador de historia antigua. Por defecto, el Marcador de Historia Antigua se reinicia en la LGE cada 3 minutos. Para poner manualmente el Marcador de Historia Antigua en la LGE, ejecute el conjunto de comandos make AHM now.
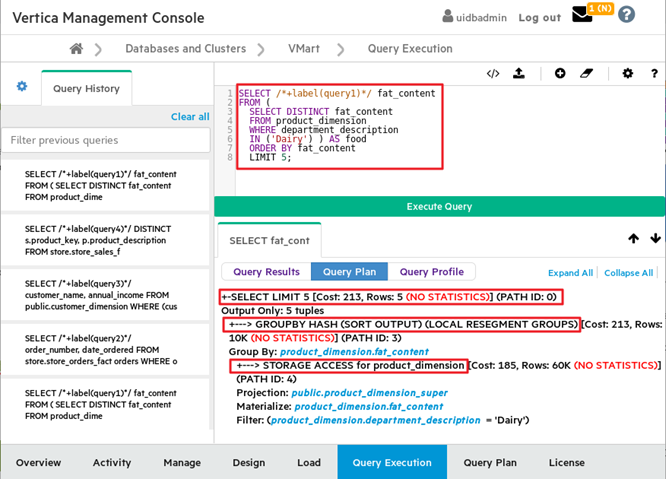
4. Visualizar un plan de consulta
El propósito de este tip es identificar cual es el plan de consulta que se está generando en la query para poder optimizar su actuación.
Desarrollo: Podremos hacer uso tanto de la consola de Vertica como de cualquier otro cliente. Si nos vamos a la consola, en la opción de Query Execution podremos ejecutar una query y comprobar su plan de consulta.
Este nos va a mostrar la información del plan que está generando el optimizador para la query planteada. La forma correcta de leer este plan es de abajo hacia arriba, haciendo una especie de ingeniería inversa.
1. El primer paso (Storage Access) es la tarea que está realizando cada uno de los nodos ejecutores. Lo primero es acceder a las zonas de memoria para obtener la información almacenada. Es importante destacar el coste (un número mayor implica mayor coste) de acceso a dichos datos y la cantidad de filas obtenidas. Una buena estructura de almacenamiento va a garantizar un bajo coste de acceso a disco. Recordemos que el cuello de botella en cuanto a la actuación de las bases de datos actuales, son los accesos a disco.
2. En segundo lugar, los datos leídos por los ejecutores se transportan hasta el nodo iniciador (el iniciador también se comporta como ejecutor). Es en este nodo, en el cual se realiza el group by de los datos, siendo también destacable el coste del proceso, pudiendo aliviar este seleccionando las claves correctas. En caso de realizar este group by, sería recomendable haber establecido dicho campo como clave de segmentación, permitiendo que esta acción sea óptima.
3. Por último, los datos son enviados al cliente para su visualización.
Tras analizar el plan que genera el optimizador, es necesario replantear la estructura de nuestras proyecciones para poder mejorar nuestras consultas. Algunas de las recomendaciones son las siguientes:
· Establecer un orden en la creación de la proyección para poder disponer de nuestros datos ya optimizados. Si almacenamos la información ordenada, estos datos no serán ordenados cuando los solicitemos, aliviando consultas de order by o group by.
· Aplicar la codificación correcta de los datos, puesto que, dependiendo del tipo de dato, esta codificación va a permitir reducir la cantidad de datos almacenados. Esto se traducirá en un mejor rendimiento.
· Seleccionar las claves correctas en la segmentación de la proyección para mejorar el rendimiento de nuestras querys.
5. Visualización de las épocas
El propósito de este tip es identificar cuáles son las épocas en las cuales se han almacenado los datos.
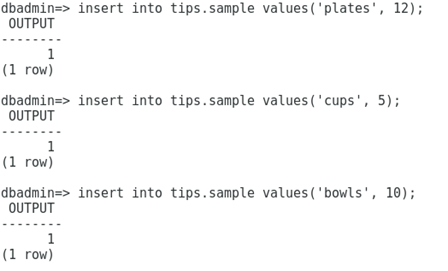
Desarrollo: Para obtener las épocas en las cuales se al almacenado los datos, basta con ejecutar consultas SQL por medio de un cliente como Dbeaver o vsql. Supongamos que disponemos de la siguiente tabla:

Vamos a realizar 3 inserciones en dicha tabla, las cuales se muestran a continuación:
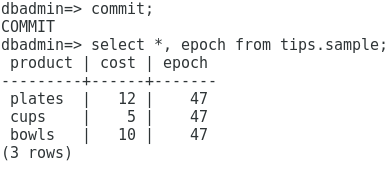
Si ahora nosotros consultamos cual es la LGE (Last Good Epoch) actual para los datos almacenados en la tabla, nos vamos a dar cuenta que no hay una asignación para ellos:

Esto se debe a que no hemos realizado un commit, en el momento en el que lo hagamos, estos datos pasarán a disponer de un valor para su época:
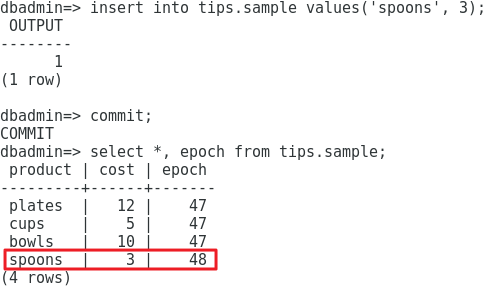
Si ahora nosotros volvemos a insertar datos, commiteamos estos y los visualizamos, podremos ver como estas épocas han variado.
De forma adicional, también podremos observar las diferentes épocas en las cuales se encuentra la base de datos mediante las siguientes consultas:

Para modificar el valor de AHM hasta LGE de forma manual, basta con ejecutar la siguiente instrucción:

6. Restaurar base de datos a una época anterior
El propósito de este tip es solventar una incoherencia en torno a las épocas, cuando la base de datos se cae tras un error en una query delete/update.
Desarrollo: Como punto de partida, ya sea porque la base de datos ha caido o porque hemos tenido que parar la instancia debido a un bloqueo, al volver a iniciar los nodos, estos provocan un error como el siguiente:
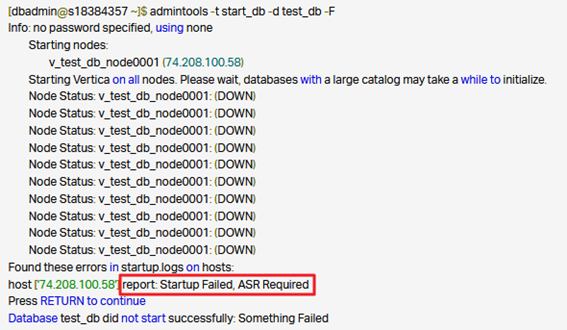
Este error se debe a una parada inesperada de la base de datos, en la cual se estaban realizando sentencias delete o update. Esta parada inesperada provoca que la LGE (Last Good Epoch) no se actualizara y al tratar de levantar los nodos, hay una incongruencia en cuanto a las épocas de los datos.
Para solventar dicho problema, deberemos restaurar nuestros datos a un estado anterior, indicándole hasta que época son fiables los datos. Para esto no vamos a poder emplear ningún cliente como Dbeaver o vsql, deberemos leer los ficheros de control y emplear los scripts de los que Vertica dispone para la instalación/actualización de la arquitectura y base de datos.
En primer lugar, para poder visualizar cual es la última época a la cual podemos regresar, vamos a emplear la siguiente instrucción:
/opt/vertica/bin/admintools -t return_epoch -d database_name
Tras esta comprobación podremos volver a esta época simplemente restaurándola por medio de la herramienta AdminTools. Esto modificará el valor de las épocas para solo contemplar los datos que pertenecen a LGE y posteriormente levantará la base de datos, estando ahora sí, operativa.
/opt/vertica/bin/admintools -t restart_db -e last