*Actualizado. Inscríbete al webinar para conocer todo sobre Talend gratuitamente:
Talend, conoce la mejor solución para Gobierno del Dato e Integración
14 de abril 10:00h-11:30h
Registro
Tip 1: Jobs explicativos
Resumen: El propósito de este tip es recordar la importancia de realizar proyectos con componentes descriptivos.
Dificultad: 1
Utilidad: 5
Desarrollo: Establecer a los repositorios, proyectos y trabajos nombres descriptivos que sean intuitivos y significativos.
Además, dentro de los jobs, para cada componente agregar una nota que especifique su función. Así cualquier compañero que visualice después el job, entenderá la función de cada uno de sus componentes y por lo tanto, la funcionalidad/objetivo completa del job
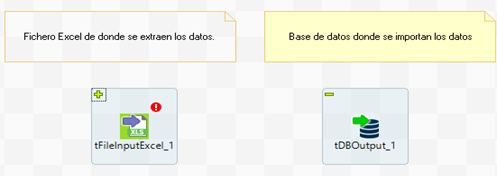
Algunos consejos:
· Utilizar letras mayúsculas para los inicios de palabra. Por ejemplo, Fichero_De_Entrada.
· Evita los espacios en blanco y utilizar guiones bajos en su lugar.
· Utilizar solo caracteres alfanuméricos.
· Evitar los nombres de carpetas y jobs generales.
· Evitar abreviar ya que dificulta la comprensión lectora del job.

Tip 2: Ordenar Jobs
Resumen: Abordar la importancia de realizar Jobs completamente legibles e intuitivos.
Dificultad: 1
Utilidad: 5
Desarrollo: Colocar los componentes de un job de manera ordenada para facilitar su seguimiento. La mejor manera es en Zigzag, es decir de arriba a abajo por componentes o pre job y dentro de una misma secuencia de izquierda a derecha.

Tip 3: Componente TRunJob
Resumen: El objetivo de esta sección es explicar la utilidad y funcionamiento del componente tRunJob.
Dificultad: 1
Utilidad: 5
Desarrollo: Cuando se tengan trabajos con muchos componentes, el mantenimiento y entender su funcionamiento se complica. Por ello, siempre que sea posible se deben de subdividir los trabajos en trabajos sencillos, lo que se conoce como subtrabajos.
A veces estos subtrabajos realizan tareas aisladas y aparecen como un conjunto sombreado en el área de trabajo formado por varios componentes. Además, los subjobs se pueden relacionar con otros subjobs mediante el disparador On SubJob. Por ejemplo, en el siguiente job padre se pueden observar hasta cinco subjobs relacionados.
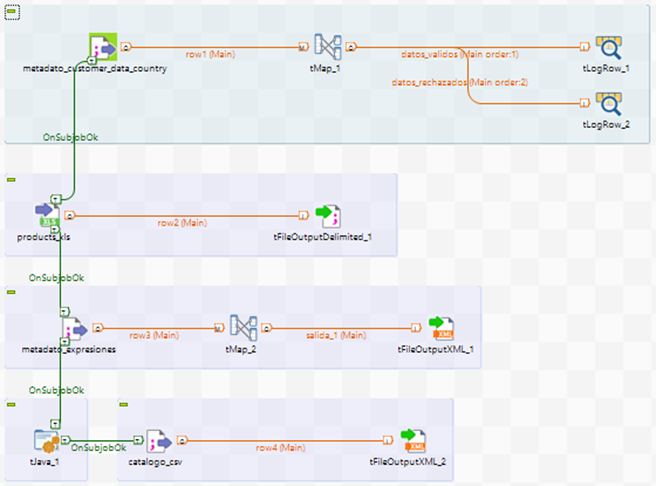
Sin embargo, el componente tRunJob permite unificar todos los componentes del subjob en uno solo dentro del job padre. Es recomendable que los subjobs dependientes de otros subjobs no formen más de tres niveles de dependencia.
El anterior ejemplo utilizando este componente quedaría así:
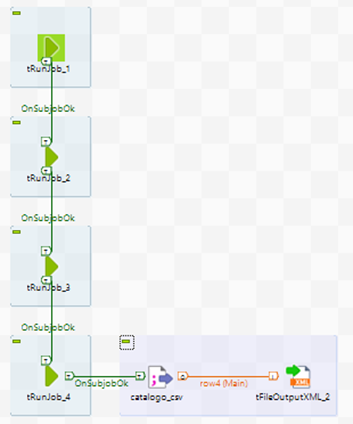
Por ello, en aquellos jobs que tienen un gran número de subjobs, es útil utilizar el componente tRunJob para reemplazar estos conjuntos de muchos componentes.
Además, este componente (tRunJob) posee una característica muy útil a la hora de ejecutar subjobs dependientes de otros y es que DESMARCANDO la opción Die on child error, se consigue que el job padre no se detenga por la ejecución errónea de uno de los subjobs.
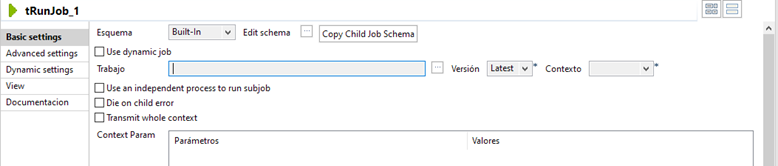
Sin embargo, si se quiere realizar un control de errores, esta característica se debe de dejar marcada e incluir disparadores del tipo OnSubjobError.
Tip 4: Joblets (Enterprise license)
Resumen: El propósito de esta funcionalidad es conseguir una mayor reutilización y refactorización del código.
Dificultad: 1
Utilidad: 5
Desarrollo: Un Joblet es un componente específico que proporciona la reutilización y la refactorización del código,cuya funcionalidad es reemplazar los grupos de componentes del job. Se pueden reutilizar más de una vez en un mismo job e incluso en jobs diferentes. No afectan al rendimiento ya que no influyen el tiempo de ejecución del job.
Utilizar tRunJob o Joblets dependerá de los requisitos comerciales establecidos. Sin embargo, su principal diferencia (dejando de lado que los Joblets pertenecen a una versión No gratuita) es que tRunJob se ejecuta como un trabajo secundario, ya que es una clase Java separada y Joblet es solo una agrupación y refactorización de algunos componentes, que forma parte de la clase principal Java del trabajo.
Además, un joblet puede acceder a las variables de contexto del trabajo principal y tRunJob solamente a las propias del componente.
Tip 5: Comandos TPreJob y TPostJob
Resumen: El objetivo de esta sección es explicar la utilidad y funcionamiento de los componentes tPreJob y tPostJob.
Dificultad: 1
Utilidad: 5
Desarrollo: Como su nombre indica estos componentes se ejecutan o antes o después que el resto de componentes de un trabajo. Por ello como buena práctica es aconsejable inicializar un job con un tPreJob invoque las variables de contexto, establezca conexiones y registre la información necesaria para comenzar la ejecución del job. Del mismo modo utilizar tPostJob, para una vez ejecutado el flujo del trabajo, cerrar las conexiones y vaciar los registros utilizados
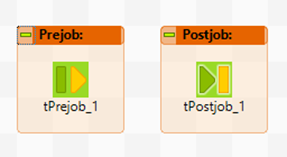
Tip 6: Comandos TWarn y TDie
Resumen: El propósito de este tip es explicar el uso de los componentes tWarn y tDie.
Dificultad: 1
Utilidad: 5
Desarrollo: Estos componentes sirven para lograr un control sobre el flujo de un trabajo. De esta manera en caso de no realizarse una correcta ejecución del trabajo, ambos componentes realizarán su función de avisar del error y realizar su tarea de recuperación o finalización de error.

Un job de ejemplo con estos dos componentes es el siguiente:
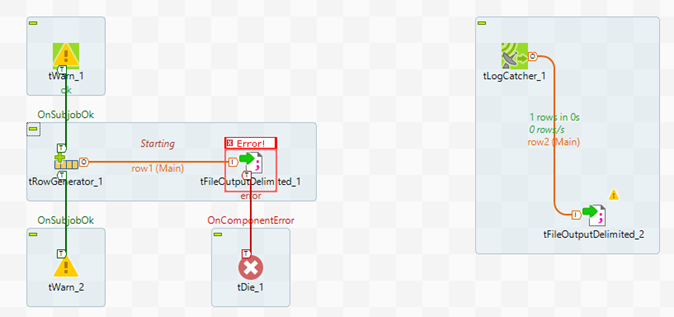
En este job, se crean una serie de registros simulados con el componente tRowGenerator. De este componente se extraen dos disparadores OnSubjobOK que avisarán si hay alguna advertencia al ejecutar el job. Después se realiza una exportación de los registros generados a un fichero que no existe para provocar el error. Dado que el job no logra localizar el fichero que se incluye en sus preferencias, se procede con el disparador Error que actúa capturando el error de ejecución del job.
Después el subjob de la parte derecha se encarga de escuchar los eventos del job mediante el componente tLogCatcher, y como se ha capturado un error, escribe el error en un fichero de texto de salida. En este fichero se registra el siguiente error, el cual coincide con el escenario provocado donde el fichero en el que se intentan insertar los registros no existe.

Mediante la orquestación de los componentes tWarn y tJob junto a un subjob que se encarga de escribir los errores captados en un fichero, de una manera sencilla se consigue conocer el error de ejecución de un job.
Tip 7: Nomenclaturas y localización de Workspaces
Resumen: El objetivo de esta sección es indicar la importancia de establecer una nomenclatura correcta a los distintos componentes de un proyecto, así como la ubicación idónea de los Workspaces de trabajo.
Dificultad: 1
Utilidad: 5
Desarrollo:
Como buena práctica es necesario establecer nomenclaturas según unas convenciones. Estas convenciones de nomenclatura dependerán del equipo de desarrollo con el que se esté trabajando o las acordadas con el cliente. Sin embargo, son muy importantes ya que permiten que el resto de desarrolladores y usuarios finales comprendan intuitivamente y de manera sencilla el obejtivo de un job o componente.
A su vez, al iniciar Talend Open Studio, es importante seleccionar Workspaces localizados en rutas distintas a la de la herramienta. Es decir, en local se debe de ubicar un workspace en una ruta distinta a la de la carpeta de Talend Open Studio, que contiene el ejecutable y otros ficheros de la herramienta. Por ejemplo, si TOS está ubicado en C:/Program Files, establecer el Workspace en C:/Documents.
Tip 8: Contextos, variables de contexto y grupos de contexto
Resumen: Explicación de la creación y utilidad de los grupos de variables de contexto.
Dificultad: 3
Utilidad: 5
Desarrollo: En Talend, la palabra contexto puede hacer referencia a tres términos:
· Variable de contexto: es un registro variable, que como su nombre indica, permite cambiar su valor, y además, se puede establecer en tiempo de compilación o en tiempo de ejecución.
· Contexto: es el entorno en el que actúa o tiene valor la variable de contexto. Normalmente los contextos son desarrollo, pruebas y producción. Una variable de contexto puede tomar un valor diferente para cada entorno.
- Grupo de contexto: es un grupo de variables de contexto que se empaquetan juntas para facilitar su uso. Los grupos de contexto permiten almacenar y reutilizar variables de contexto en distintos jobs y proyectos de manera sencilla.
Si por ejemplo se necesita iniciar sesión en una cuenta con su correspondiente contraseña, estas se pueden almacenar como variables de contexto dentro de un grupo de contexto y hacer referencia/uso de ellas en diversos jobs o entornos.
Para crear un grupo de contexto, desde la pestaña Repositorio, click derecho sobre Contexts -> Create context group.

Se define su nombre, descripción, y estado.
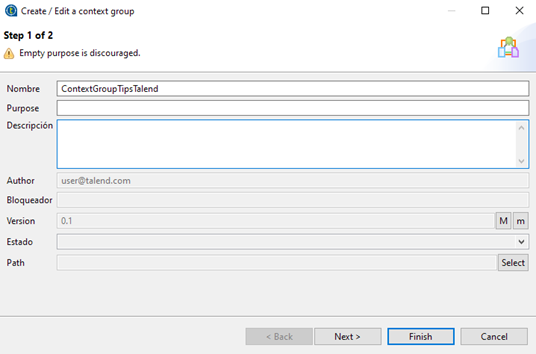
Después se agregan las variables (botón inferior izquierdo +), definiendo su tipo y su valor.

También se pueden configurar las mismas variables para diferentes entornos, por ejemplo, local, pruebas y producción. Para ello se debe de establecer un contexto de ejecución (botón superior derecho +).

Después se edita el valor de la variable para cada contexto de ejecución.
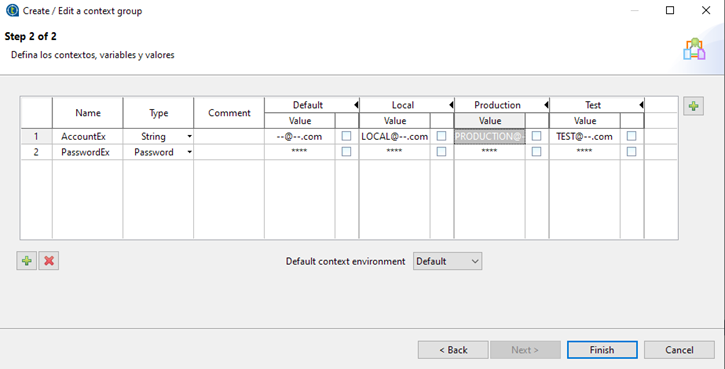
Por último, para utilizar estos grupos de contexto en un job, simplemente se debe de seleccionar la pestaña Contexts (centro inferior) y el botón
En la pestaña emergente se selecciona el grupo de contexto que se desea utilizar.

Posteriormente, cuando se quiera ejecutar el job, se puede decidir sobre que entorno hacerlo simplemente seleccionando el contexto de ejecución. Desde la pestaña Run:
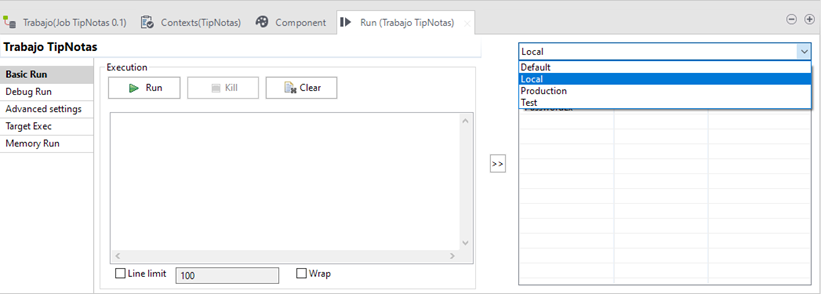
Gracias a los grupos de contexto y a los contextos de ejecución, se puede acceder a variables o entornos establecidos, de una manera muy sencilla y rápida en distintos Jobs e incluso proyectos.
Tip 9: Componente TMap
Resumen: El propósito de este tip es explicar el uso y funcionamiento del componente tMap.
Dificultad: 1
Utilidad: 5
Desarrollo: Este componente se encarga de mapear un flujo de datos desde una entrada hasta una salida.
Sin embargo, es un componente que puede llegar a trabajar con miles de filas, por ello hay que prestar atención a su rendimiento en cuanto a memoria se refiere. En función de los objetivos se pueden elegir tres modelos de búsqueda:
· Load once: lee todos los registros de la memoria.
· Reload at each Row: lee cada fila para cada registro.
Reload at each Row (caché): lee cada fila para cada registro y se almacena en caché.

Tip 10: Modelo de datos (buenas prácticas) y tipos.
Resumen: El objetivo de esta sección es concienciar de la importancia de representar los datos a través del modelo de datos más característico para cada escenario, así como una serie de tips a seguir a la hora de construir modelos de datos.
Dificultad: 2
Utilidad: 5
Desarrollo: Siempre que los requisitos técnicos lo permitan, se deben crear modelos adaptativos y exponenciales, es decir, modelos que permitan modificaciones o actualizaciones en su estructura y que permitan su adaptación a un conjunto de datos superior.
Los modelos deben de ser óptimos, portables y eficientes para poder alojarse en tipos de sistemas similares con el mayor rendimiento posible.
La creación de un modelo de datos debe de seguir el siguiente ciclo:
1. Comprender el conjunto de datos con el que se va a trabajar
2. Presentar el modelo de datos que mejor se adapte al conjunto de datos.
3. Validar el correcto funcionamiento del modelo en distintos escenarios y bajo distintos requisitos.
4. Crear y desarrollar el modelo de datos.
5. Validar que el modelo de datos cumple todos los requisitos sin empeorar su rendimiento y eficiencia.
Existen diferentes modelos de datos que se utilizan para visualizar la información que se quiere analizar desde distintas perspectivas. Como buena práctica, a la hora de presentar a un usuario final un modelo de datos basado en su conjunto de datos, lo idóneo es crear cuatro tipos de modelos de datos, el holístico, el conceptual, el lógico y el físico.
Cada uno de ellos permite de una determinada manera, que el usuario final comprenda el modelo que siguen/forman sus datos. En función de los conocimientos o del grado de detalles que se quiera quiera conocer, el modelo presentado será uno u otro.
· Modelo de datos holístico:
Este modelo representa los datos empresariales de manera general, con el objetivo de identificar y abstraer el conjunto de datos de toda la empresa. Es decir, en el menor nivel de detalle se describe todo lo que existe en cuanto a datos en una empresa, relaciones y organización. Se suele utilizar un gráfico de burbujas para representar el modelo de datos holísticos.
· Modelo de datos conceptual:
El modelo conceptual representa de manera abstracta todas las entidades y sus relaciones. Los diagramas UML son los que mejor dibujan este modelo.
· Modelo de datos lógicos:
La capa lógica representa una estructura abstracta de información organizada en términos de entidades, sus atributos y relaciones específicas entre ellos. Este modelo de datos derivado del modelo conceptual, define los detalles y las relaciones entre las entidades, sin tener en cuenta ninguna tecnología de almacenamiento específica. Las entidades pueden representar un solo elemento, parte de un elemento o múltiples elementos y se agregan en ellas atributos específicos. Los diagramas Entidad / Relación son los más adecuados para representar los modelos de datos lógicos.
· Modelo de datos físicos:
La capa física representa objetos de datos físicos y su configuración de almacenamiento derivados de un modelo de datos lógico. Este modelo de datos incorpora tablas, columnas, tipos de datos, claves, índices, vistas y detalles sobre la información proporcionada por el conjunto de datos. Generalmente, este tipo de modelos depende del producto software que se utilice para el desarrollo del proyecto.
|
ASPECTO DEL MODELO DE DATOS |
HOLÍSTICO |
CONCEPTUAL |
LÓGICO |
FÍSICO |
|
Conjunto de datos |
|
|
|
|
|
Relaciones del conjunto de datos |
|
|
|
|
|
Nombres de los objetos |
|
|
|
|
|
Relaciones de los objetos |
|
|
|
|
|
Generalización de los objetos |
|
|
|
|
|
Nombres de las entidades |
|
|
|
|
|
Relaciones entre las entidades |
|
|
|
|
|
Claves de la entidad |
|
|
|
|
|
Atributos de la entidad |
|
|
|
|
|
Restricciones de entidad |
|
|
|
|
|
Nombres de las tablas |
|
|
|
|
|
Nombres de las columnas/campos |
|
|
|
|
|
Tipos de datos de las columnas |
|
|
|
|
|
Valores predeterminados de las columnas |
|
|
|
|
|
Claves primarias/secundarias |
|
|
|
|
|
Configuraciones de almacenamiento |
|
|
|
|
Más info útil sobre Talend:
 Emilio
Emilio Emilio
Emilio Emilio
Emilio Emilio
Emilio Emilio
Emilio Admin
Admin Admin
Admin Admin
Admin Admin
Admin Admin
Admin