

- x50 faster 'near real time' Big Data OLAP Analytics Architecture
- Use Case “Dashboard with Kylin (OLAP Hadoop) & Power BI”
- Cuadros de mando con Tableau y Apache Kylin (OLAP con Big Data)
- BI meet Big Data, a Happy Story
- 7 Ejemplos y Aplicaciones practicas de Big Data
- Analysis Big Data OLAP sobre Hadoop con Apache Kylin
- Real Time Analytics, concepts and tools
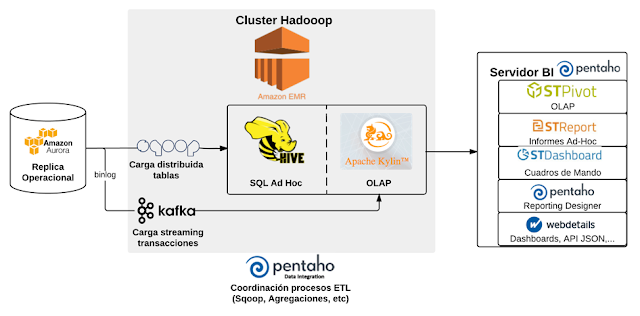
- Hadoop Hive y Pentaho: Business Intelligence con Big Data (Caso Practico)
Hoy os vamos a contar sobre otras alternativas gracias a Roman Lementov :
I want to compare ClickHouse , Druid and Pinot , t he three open source data stores that run analytical queries over big volumes of data with interactive latencies.
ClickHouse, Druid and Pinot have fundamentally similar architecture, and their own niche between general-purpose Big Data processing frameworks such as Impala, Presto, Spark, and columnar databases with proper support for unique primary keys, point updates and deletes, such as InfluxDB.
Due to their architectural similarity, ClickHouse, Druid and Pinot have approximately the same “optimization limit”. But as of now, all three systems are immature and very far from that limit. Substantial efficiency improvements to either of those systems (when applied to a specific use case) are possible in a matter of a few engineer-months of work. I don’t recommend to compare performance of the subject systems at all, choose the one which source code you are able to understand and modify, or in
which you want to invest.
Among those three systems, ClickHouse stands a little apart from Druid and Pinot, while the latter two are almost identical, they are pretty much two independently developed implementations of exactly the same system.
ClickHouse more resembles “traditional” databases like PostgreSQL. A single-node installation of ClickHouse is possible. On small scale (less than 1 TB of memory, less than 100 CPU cores).
ClickHouse is much more interesting than Druid or Pinot, if you still want to compare with them, because ClickHouse is simpler and has less moving parts and services. I would say that it competes with InfluxDB or Prometheus on this scale, rather than with Druid or Pinot.
Druid and Pinot more resemble other Big Data systems in the Hadoop ecosystem. They retain “self-driving” properties even on very large scale (more than 500 nodes), while ClickHouse requires a lot of attention of professional SREs. Also, Druid and Pinot are in the better position to optimize for infrastructure costs of large clusters, and better suited for the cloud environments, than ClickHouse.
The only sustainable difference between Druid and Pinot is that Pinot depends on Helix framework and going to continue to depend on ZooKeeper, while Druid could move away from the dependency on ZooKeeper. On the other hand, Druid installations are going to continue to depend on the presence of some SQL database.
Currently Pinot is optimized better than Druid. (But please read again above — “I don’t recommend to compare performance of the subject systems at all”, and corresponding sections in the post.)