1. Introducción
Dagster es una plataforma para la orquestación de flujos de datos. Dagster permite la creación de ‘Jobs’ (o ‘Trabajos’) que orquestan el flujo de datos entre componentes lógicas llamadas ‘Ops’. El desarrollo de los ‘Jobs’ puede hacerse de manera local y desplegarse en cualquier sitio.
Dagster se instala como una API en Python y permite utilizar toda la potencia del lenguaje para desarrollar los procesos de transformación de datos. Además, cuenta con una rica interfaz de usuario que proporciona información de la ejecución de los Jobs.
En este documento comentaremos algunos de los conceptos de Dagster y realizaremos un ejercicio con una implementación análoga en otra herramienta de procesos de ETL y flujo de datos, como Pentaho Data Integration.
Referencias
La página principal de Dagster es https://dagster.io/
La documentación y un tutorial de inicio se pueden consultar en https://docs.dagster.io/getting-started
El github puede encontrarse en https://github.com/dagster-io/dagster/tree/0.13.17
También es interesante este artículo para comprender las diferencias entre Dagster y Airflow: https://dagster.io/blog/dagster-airflow
Algunas de las imágenes de este documento provienen de la documentación oficial de Dagster.
Instalación
Dagster puede instalarse mediante pip. Una vez tengamos instalados Python y pip en nuestro PC, es tan fácil como ejecutar el comando:
pip install dagster
La interfaz de usuario que proporciona Dagster se llama Dagit, y también puede instalarse mediante pip:
pip install dagit
2. Conceptos principales
Dagster define los flujos de trabajo mediante 3 estructuras lógicas: Ops, Jobs y Graphs.
A. Ops
Son la unidad principal de computación de Dagster. En otras plataformas o herramientas de ETL vemos este concepto bajo el nombre de “Transformaciones” o “Pasos”. Varias Ops pueden conectarse para crear un Graph (Grafo).
Para seguir unas buenas prácticas de diseño y desarrollo, cada Op individual debe realizar tareas relativamente simples, de manera que una vez interconectadas formando un Graph, pueda realizar tareas de complejidad superior. Estas tareas simples pueden ser, por ejemplo, la ejecución de una query en base de datos, hacer una llamada a una API y almacenar el resultado, enviar un email, aplicar una transformación de datos a un dataset…
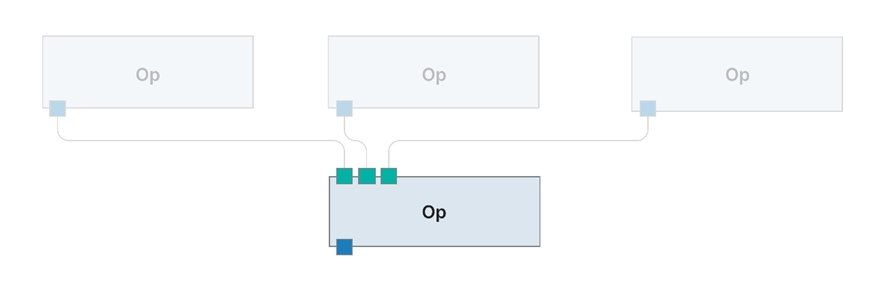
Algunos conceptos relacionados en el desarrollo y empleo de las Ops son:
· Resources: Cuando desarrollamos procesos ETL, es habitual utilizar o interactuar con sistemas externos, ya sean bases de datos, APIs… Dagster utiliza Resources para abstraer la configuración de estas conexiones externas para poder independizar el desarrollo de la Op del entorno en el que finalmente quiere lanzarse. Por ejemplo, es muy común utilizar una base de datos distinta durante el desarrollo respecto a la base de datos final de producción.
· Input y Output: Cada Op admite inputs y output definidos de manera análoga a los parámetros de entrada y salida de una función de Python. Dagster proporciona una clase “Dagster Type” que permite anotar los tipos de datos que admite cada Op tanto de entrada como de salida para poder validar el funcionamiento durante la ejecución.
· Configuration: Se puede dar un esquema de configuración a cada Op para gestionar los parámetros de entrada a cada Op. Estos parámetros se gestionan en el Context de cada Op.
· Events: Cada Op emite un flujo de Eventos que facilitan la inspección, debug y monitorización de los Jobs en ejecución.
Otras características de las Ops que pueden destacar son el desarrollo independiente de la ejecución, de manera que puedan desarrollarse y desplegarse en producción sin modificar nada, y la facilidad de testeo.
B. Graphs
Los grafos representan las conexiones entre Ops mediante dependencias de datos. Las Ops se enlazan definiendo las dependencias que existen entre sus Inputs y Outputs. En Dagster, estas dependencias se expresan como dependencias de datos, no únicamente dependencia de ejecuciones. De esta manera, Dagster no se limita a asegurar únicamente que el orden de ejecución es el correcto.
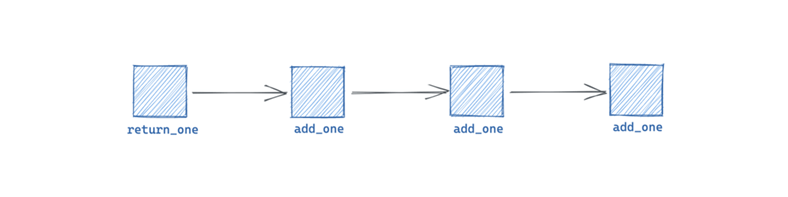
C. Jobs
Un Job es la unidad principal de ejecución y monitorización en Dagster. Un job es un grafo de ops ejecutable, con configuración y recursos opcionales.
Se pueden crear Jobs desde 0 (de la misma manera que se crearía un grafo), o a partir de grafos. La creación a partir de grafos permite reutilizar la misma estructura lógica de la conexión de Ops en diferentes Jobs con diferente configuración.
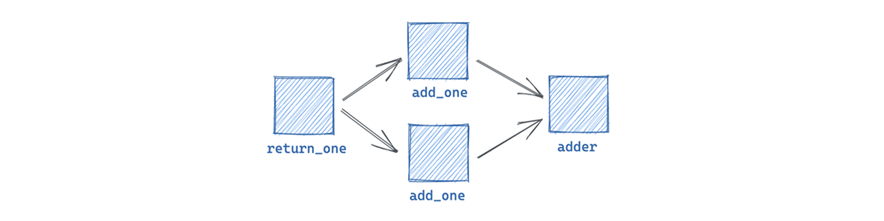
3. Creación de ops, jobs y graphs
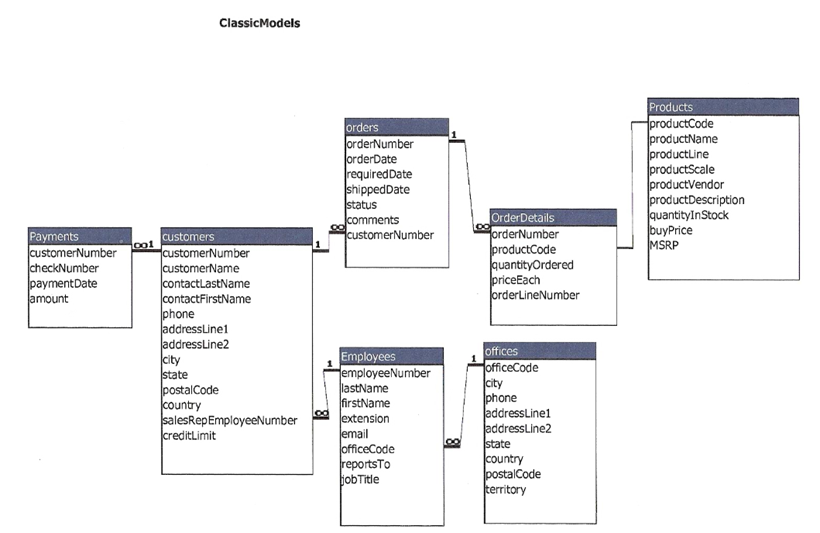
Para ilustrar los conceptos anteriores y ver un caso de ejemplo de un proceso de ETL, vamos a simular una situación en la que queremos construir un Data Mart a partir de la base de datos origen cuyo esquema ER es:
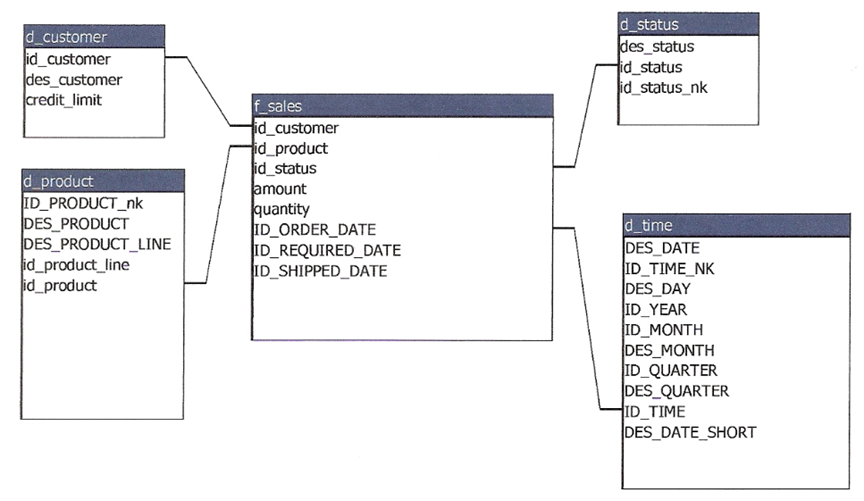
El esquema del Data Mart final es:
En este apartado vamos a crear la dimensión ‘d_customer’ a partir de la tabla de origen ‘customers’. Es un ejemplo sencillo que ilustra el proceso ETL: extraer los datos, transformarlos y cargarlos. Lo haremos de manera análoga a cómo lo haríamos en PDI.
Para cargar la dimensión Customer, en PDI aplicaríamos la siguiente transformación:
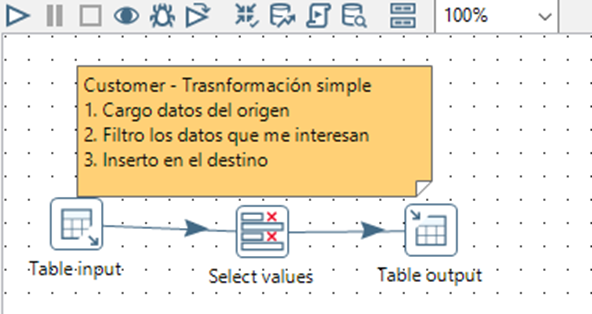
Necesitamos, por tanto, conectarnos a la base de datos, importar los datos, filtrarlos e insertarlos en la base de datos destino. Por seguir el planteamiento análogo, en Dagster vamos a crear una Op por cada uno de los 3 pasos anteriores, aunque si fuera necesario podríamos encapsularlo en un menor número de Ops.
Antes de nada, debemos importar las librerías que necesitemos, en mi caso Dagster, MySQL ya que la base de datos está en un MySQL y pandas para manipular los datos.
from dagster import op, job, get_dagster_logger, graph
import mysql.connector
import sqlalchemy
import pandas as pd
Cada Op se representa mediante una función de Python. Para definir una Op necesitamos usar la anotación @op. Dentro de la función aplicamos toda la lógica para llevar a cabo el proceso que queramos. Dado que queremos extraer los datos de la tabla, necesitaremos abrir una conexión a la base de datos y ejecutar una sentencia de Select:
@op
def extract_customers():
conn =mysql.connector.connect(
host ="localhost",
user ="root",
password ="pass"
)
query = '''SELECT * FROM sampledata_etl.customers;'''
customers =pd.read_sql(query, con = conn)
return customers
Una vez hemos extraído los datos, el siguiente paso es modificarlos. Dado que se espera que la extracción se haga primero, esta dependencia de orden viene definida mediante los parámetros de entrada y salida. La transformación que aplicaremos es sencilla: cogeremos 3 columnas y renombraremos dos de ellas.
@op
def transform_customers(customer_data):
transformed_data =customer_data[['CUSTOMERNUMBER', 'CUSTOMERNAME', 'CREDITLIMIT']]
transformed_data =transformed_data.rename(columns={'CUSTOMERNUMBER': 'ID_CUSTOMER', 'CUSTOMERNAME': 'DES_CUSTOMER'})
return transformed_data
Como se puede observar, la Op de transform_customers admite como argumentos customer_data, y a su vez devuelve otro parámetro llamado transformed_data.
Por último, construimos la Op para cargar los datos en la nueva tabla. Aunque antes hemos utilizado el conector MySQL, esta vez vamos a utilizar SQLAlchemy ya que nos permite utilizar el método de pandas to_sql:
@op
def load_customers(customer_data):
engine =sqlalchemy.create_engine('mysql+mysqlconnector://root:pass@localhost:3306/sampledata_etl')
conn =engine.connect()
table_name ='d_customer'
customer_data.to_sql(name=table_name, con=conn, if_exists='replace', index = False)
conn.close()
Ahora que ya tenemos las 3 Ops, falta unirlas en un grafo.
@graph
def dim_customer():
load_customers(
transform_customers(
extract_customers()
)
)
Se puede ver fácilmente la dependencia viendo los parámetros de dentro hacia fuera: primero se ejecuta extract_customers y nos devuelve los datos de la tabla de origen. Transform_customers toma estos datos y aplica su transformación, devolviendo nuevos datos. Estos nuevos datos alimentan load_customers que los carga en una tabla de la base de datos.
Si queremos ejecutar el proceso de dim_customer, necesitamos un Job. Podemos hacerlo de dos maneras, o bien modificando la anotación @graph por @job, o bien utilizando el grafo y creando un job a partir de él:
dim_customer_job = dim_customer.to_job()
4. Ejecución de un Job
Existen 3 maneras de ejecutar un job en Dagster: en el propio script de Python, por línea de comandos, o utilizando la interfaz de usuario Dagit.
Ejecución con Dagit
Utilizaremos Dagit para ilustrar esta interfaz. Para ello, desde la ventana de comandos, navegamos hasta el directorio que tenemos guardado nuestro script con el job y ejecutamos el comando:
dagit -f customers.py
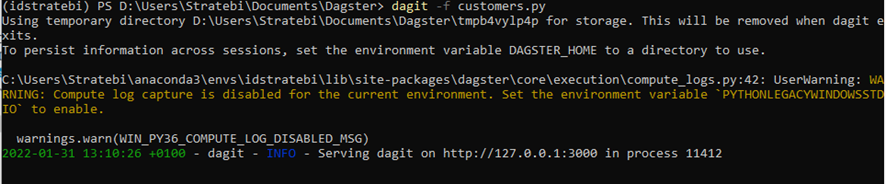
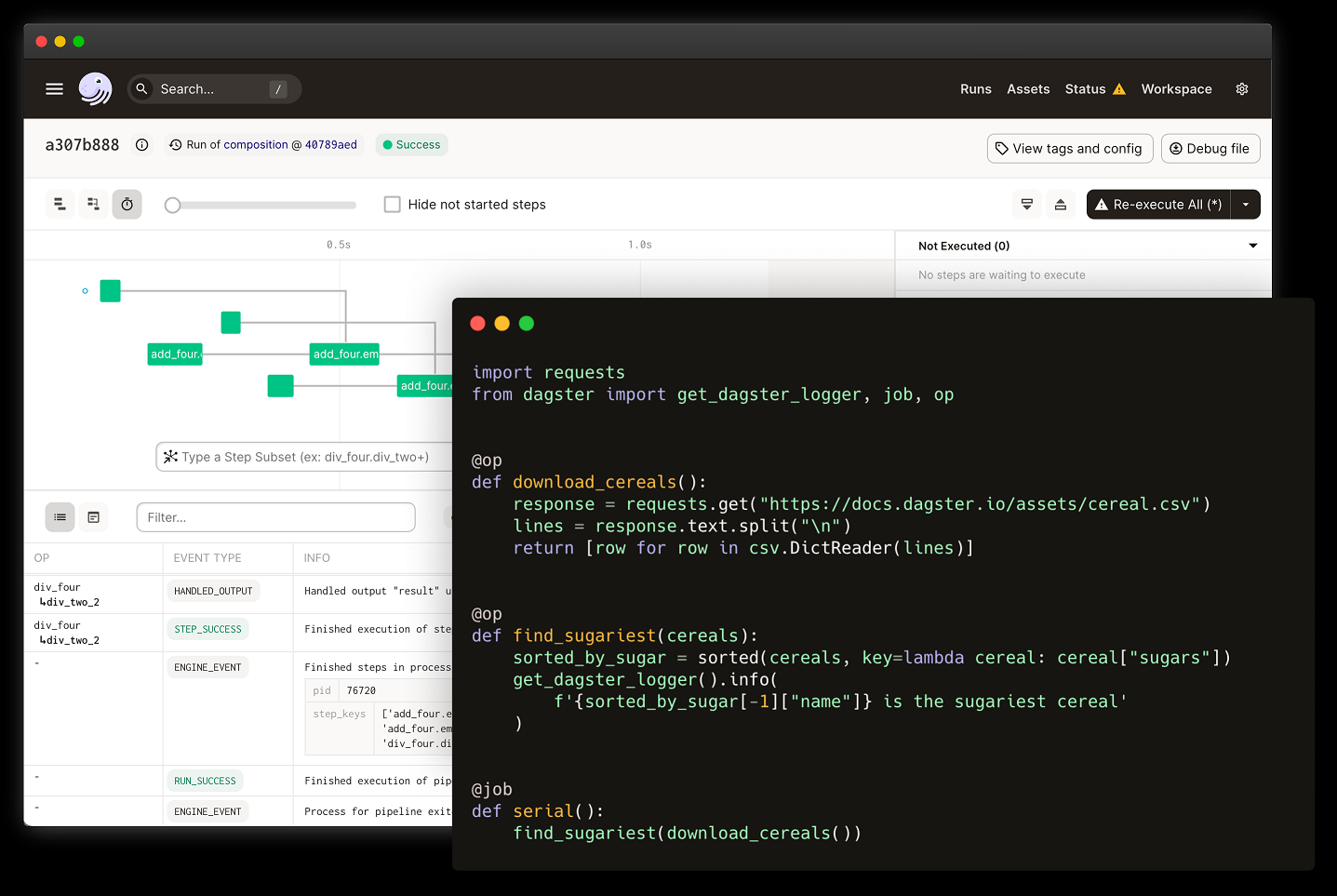
El log nos indica que tenemos dagit en la dirección 127.0.0.1:3000. Abrimos esta dirección en un navegador y nos encontramos con la interfaz de usuario que describe nuestro job:
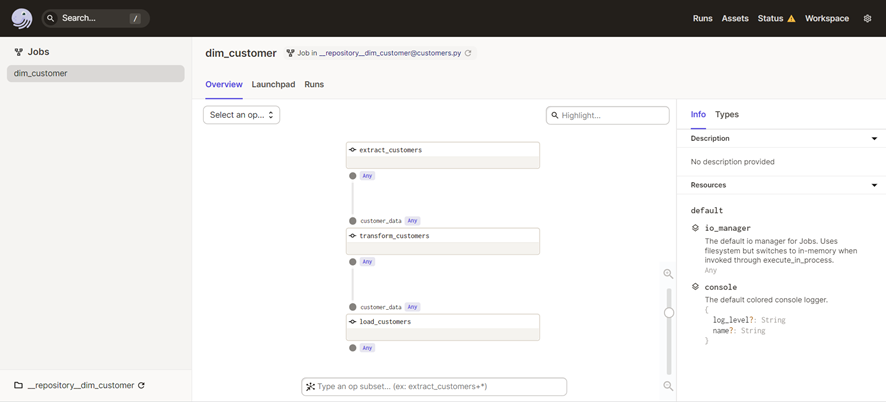
Podemos apreciar el grafo que empieza desde extract_customers y las dependencias entre cada una de las Ops que hemos creado.
Para lanzar nuestro job, hacemos click en Launchpad.
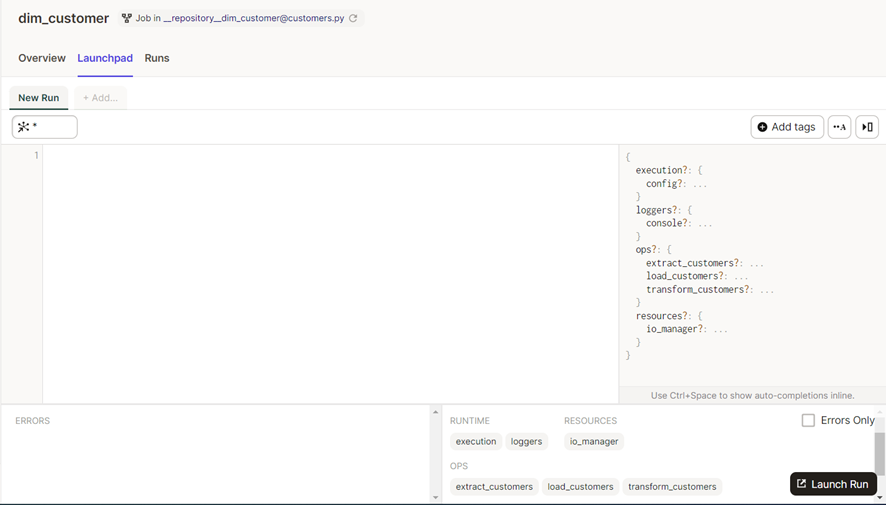
Y hacemos click en el botón de abajo a la derecha Launch Run. Esto nos lleva a la pantalla de Runs, donde podemos ver los eventos que generan las Ops que nos permiten monitorizar la ejecución en tiempo real.
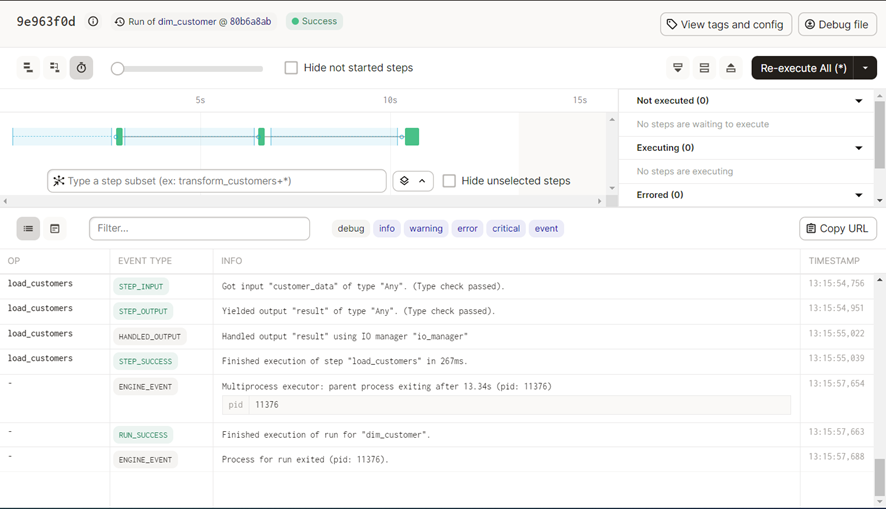
Podemos comprobar que se ha ejecutado correctamente viendo el resultado:
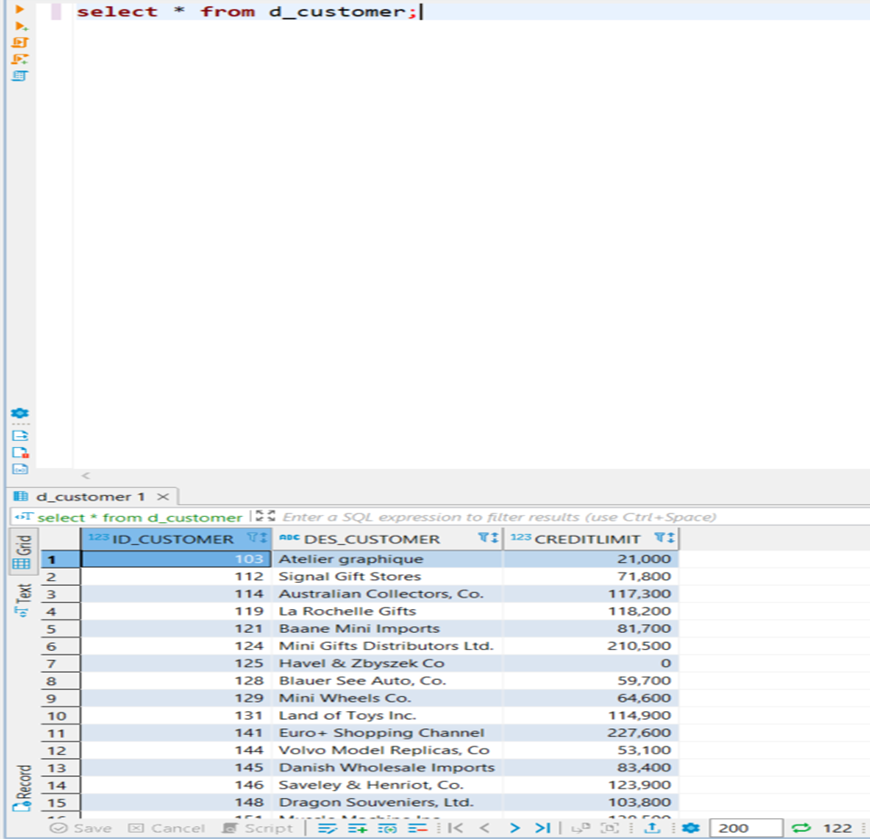
Ejecución con Python
Si quisiéramos ejecutar el job desde el script de Python, debemos añadir las siguientes líneas al código:
if __name__ == "__main__":
result =dim_customer_job.execute_in_process()
Y lo ejecutamos como cualquier script de Python.
Ejecución por línea de comandos
En la consola, desde el directorio donde tenemos el archivo customers.py, ejecutamos el comando:
dagster job execute -f customers.py
5. Conceptos avanzados
Otros tipos de flujos
En Dagster pueden aplicarse otros tipos de flujos además del secuencial (una Op detrás de otra). Supongamos que en la Op de transformación anterior, necesitamos datos adicionales que provienen de otra fuente. En este caso, la transformación no podría ejecutarse hasta no tener ambas extracciones resueltas, pero las extracciones pueden realizarse de manera independiente.
Para reflejar este hecho, añadimos la Op necesaria:
@op
def extract_additional_data():
# logica para la extraccion de datos adicionales
return1
Y modificamos la Op de transform_customers añadiéndole un nuevo argumento de entrada:
@op
def transform_customers(customer_data, additional_data):
transformed_data =customer_data[['CUSTOMERNUMBER', 'CUSTOMERNAME', 'CREDITLIMIT']]
transformed_data =transformed_data.rename(columns={'CUSTOMERNUMBER': 'ID_CUSTOMER', 'CUSTOMERNAME': 'DES_CUSTOMER'})
return transformed_data
En la construcción del grafo/job, añadiríamos la llamada a la Op adicional:
@graph
def dim_customer():
load_customers(
transform_customers(
extract_customers(),
extract_additional_data()
)
)
En Dagit vemos la nueva estructura del grafo:
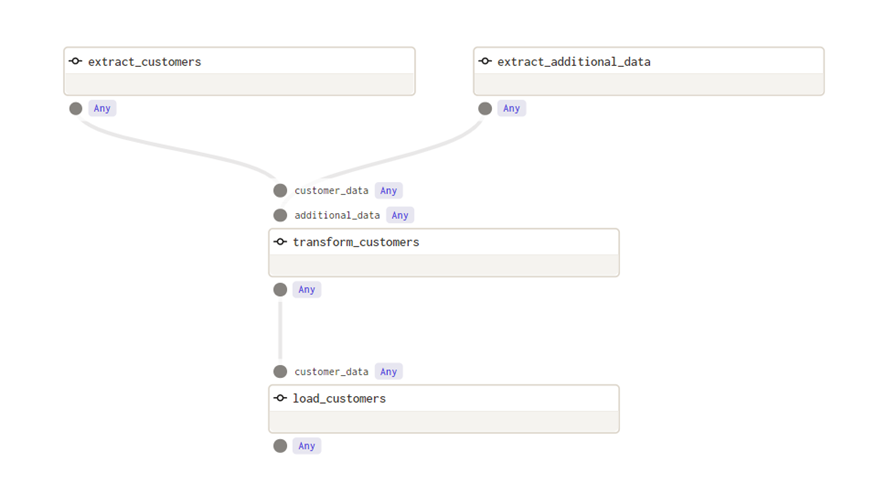
Dagster ejecuta de manera paralela ambas extracciones y además espera a obtener los resultados para ejecutar transform_customers. En la pantalla de Run vemos esta paralelización de la siguiente manera:
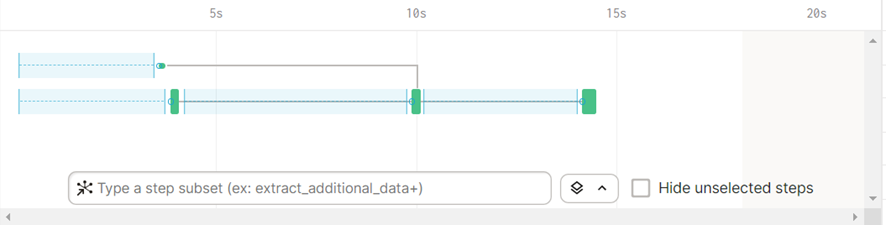
La barra superior indica la ejecución de la Op ‘extract_additional_data’ mientras que la inferior indica la ejecución de ‘extract_customers’. Dado que la llamada a extract_additional_data tarda menos, esta espera a que termine la Op de extract_customers, y una vez se tienen ambos resultados, convergen en la ejecución de ‘transform_customers’.
Además de flujos paralelos (de inputs múltiples), Dagster ofrece más tipos de diseño de flujos para crear los grafos. Se puede consultar en la documentación:
https://docs.dagster.io/concepts/ops-jobs-graphs/jobs-graphs#examples
Uso de contexto
Cada Op admite un primer parámetro llamado context que si se define, Dagster crea un objeto de contexto y se lo pasa al cuerpo de la Op. Este context da acceso a información de sistema, como la configuración de la Op, loggers, resources, run id…
En concreto, la configuración de la Op nos permite proporcionar parámetros para que las Op sean más dinámicas y reutilizables.
Tomando el ejemplo anterior, supongamos que queremos parametrizar el host de la conexión a la base de datos en la Op ‘extract_customers’.
@op(config_schema = {'host': str})
def extract_customers(context):
conn =mysql.connector.connect(
host =context.op_config['host'],
user ="root",
password ="pass"
)
query = '''SELECT * FROM sampledata_etl.customers;'''
customers =pd.read_sql(query, con = conn)
return customers
En la anotación de @op, añadimos el config_schema de manera que la configuración de la Op admitirá un parámetro llamado host que es de tipo String.
Para poder acceder a él, debemos definir el primer input como context (debe llamarse así, esto imposibilita utilizar la palabra context como nombre de input). Ahora, la Op puede acceder al contexto que contiene la op_config que hemos definido. Accedemos al host a partir de context.op_config[‘host’].
En Dagit, vemos que ahora arriba a la derecha de extract_customers, aparece la palabra ‘config’:
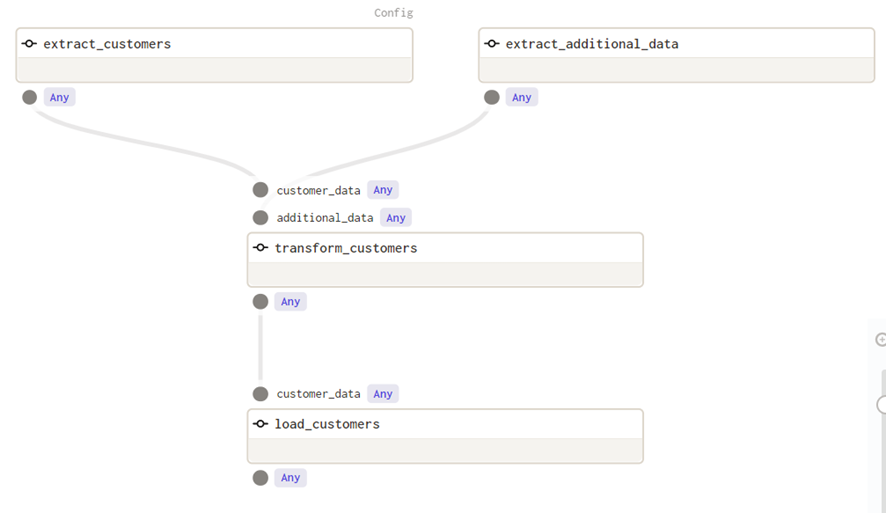
Si queremos ejecutar el Job en Dagit, debemos proporcionar la configuración necesaria. En el Launchpad, escribimos:

Si queremos ejecutar el Job en Python, proporcionamos el argumento run_config a la sentencia ‘execute_in_process’:
run_config = {
"ops": {
"extract_customers": {
"config": {"host": "localhost"}
}
}
}
if __name__ == "__main__":
result =dim_customer_job.execute_in_process(run_config = run_config)
Si queremos ejecutar el Job por línea de comandos, debe proporcionarse la configuración mediante un archivo YAML. Teniendo un archivo llamado run_config.yaml con el siguiente contenido:
ops:
extract_customers:
config:
host: “localhost”
Ejecutamos el comando:
dagster job execute -f customers.py -c run_config.yaml

6. Conclusiones
Las bases de la plataforma Dagster son sólidas: orientación al testeo, fácil desarrollo y despliegue, abstracción y reutilización de código, y potentes logs para monitorización y debug.
A la hora de comparar Dagster con herramientas de ETL más tradicionales, la principal diferencia está en el desarrollo gráfico (Drag and Drop) y el desarrollo con código. Desarrollar procesos ETL utilizando únicamente código tiene una barrera de entrada mucho más alta y habría que considerar en cada proyecto si vale la pena abordar la complejidad añadida. Al ser en código Python, aquellos proyectos que busquen implementar algoritmos de Machine Learning o inteligencia artificial, poder aplicarlos como parte del flujo de datos en Dagster será un plus. Esto hace que cada herramienta tenga su papel diferenciado.
Posts relacionados:
 Emilio
Emilio Emilio
Emilio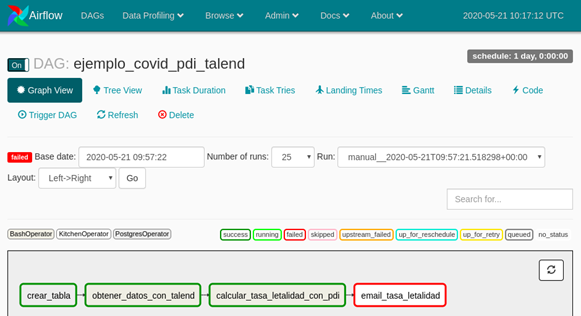 Emilio
Emilio Emilio
Emilio Emilio
Emilio Emilio
Emilio