

Vertica se trata de un almacén de datos analíticos unificado, basado en una arquitectura masivamente escalable con el más amplio conjunto de funciones analíticas que abarcan series de eventos y de tiempo, coincidencia de patrones, aprendizaje automático de bases de datos geoespaciales y de extremo a extremo.
1. Qué es Vertica
Vertica permite aplicar fácilmente estas potentes funciones a las cargas de trabajo analíticas más grandes y exigentes, dotando al usuario con conocimientos empresariales predictivos más rápido que cualquier almacén de datos analíticos del mercado. Vertica proporciona una plataforma analítica unificada a través de las principales nubes públicas y centros de datos en las instalaciones e integra los datos en el almacenamiento de objetos en la nube y en el HDFS sin obligarle a mover ninguno de sus datos.
Por cierto, tiene también una versión gratuita muy interesante
La aplicación Vertica se construyó sobre 4 objetivos principales. Remaximizar el rendimiento de la base de datos almacenando los datos en estructuras de datos orientadas a columnas muy específicas, llamadas proyecciones. La velocidad de consulta se incrementa eliminando la necesidad de escanear todos los datos en una fila de tablas. Sólo se leen las columnas que importan para la consulta. Además, los algoritmos de codificación almacenan los datos de manera eficiente, reduciendo el tiempo necesario para acceder a los datos desde el disco.
Puedes ver también una recopilación de posts en TodoBI en donde hemos hablado de Vertica
2. Proyecciones
En las bases de datos tradicionales de almacenamiento en fila, los datos se almacenan en tablas. Así que todas las consultas se hacen en disco. Cuando una consulta se envía a una base de datos tradicional de almacén de filas, cada columna de la tabla se examina para proporcionar la respuesta a la consulta.
Por lo tanto, esta consulta se ejecuta con relativa lentitud antes de devolver la respuesta. La ventaja más obvia del rendimiento de Vertica es la orientación de las columnas de los datos. Al almacenar los datos en el disco en colecciones de columnas, llamadas proyecciones, esta consulta sólo necesita leer las columnas referidas en la consulta.
Esta significativa reducción en el espacio de almacenamiento y en el IO del disco, permite un rendimiento y una respuesta mucho más rápida de la consulta. Las tablas lógicas se descomponen y se almacenan físicamente como grupos de columnas, llamadas proyecciones. Una base de datos Vertica está compuesta exclusivamente por estas estructuras de consulta optimizadas en disco, sin la sobrecarga de las tablas base.

Una proyección consiste en algún subconjunto de las columnas de una tabla. Las columnas pueden estar en cualquier orden en la proyección y la proyección puede ser clasificada independientemente por la información de las diferentes columnas. Cuando se envía una consulta, el componente optimizador de Vertica selecciona la proyección que ofrecerá el rendimiento óptimo de la consulta.
3. Codificación
Hay dos costes primarios en el procesamiento de una consulta típica, el acceso al disco y los ciclos de la CPU. El motor de consulta de Vertica funciona directamente sobre datos codificados, lo que significa que puede requerir menos operaciones de CPU para procesar la versión comprimida de una tabla.
La compresión columnar y la operación directa sobre datos comprimidos desplazan el cuello de botella en el procesamiento de consultas de los discos, que no son cada vez más rápidos, a las CPU, que son cada vez más rápidas. Los datos se decodifican lo más tarde posible y sólo cuando una consulta accede a los datos.
Esto permite que las consultas se ejecuten más eficientemente. Típicamente una base de datos Vertica ocupa hasta un 90% menos de espacio en disco que los datos cargados en ella. Esto no sólo reduce los costos de almacenamiento, sino que también acelera la consulta al reducir aún más la IO del disco. Además de la orientación en columnas de Vertica, una de las principales formas en que Vertica logra un rendimiento más rápido, es a través de la compresión en columnas.
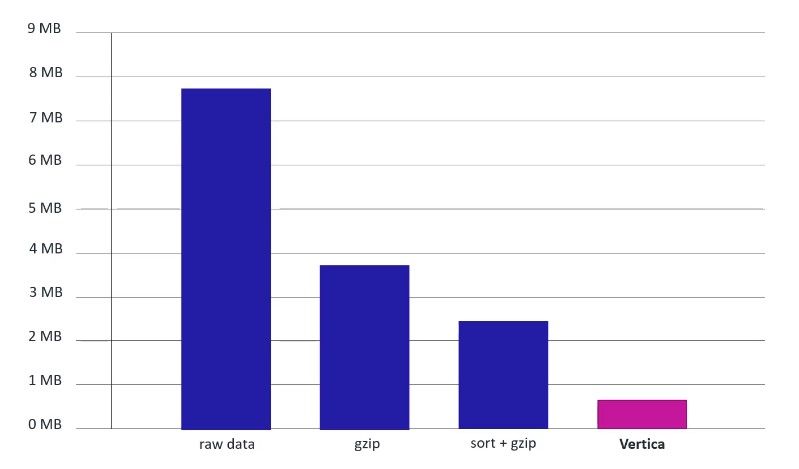
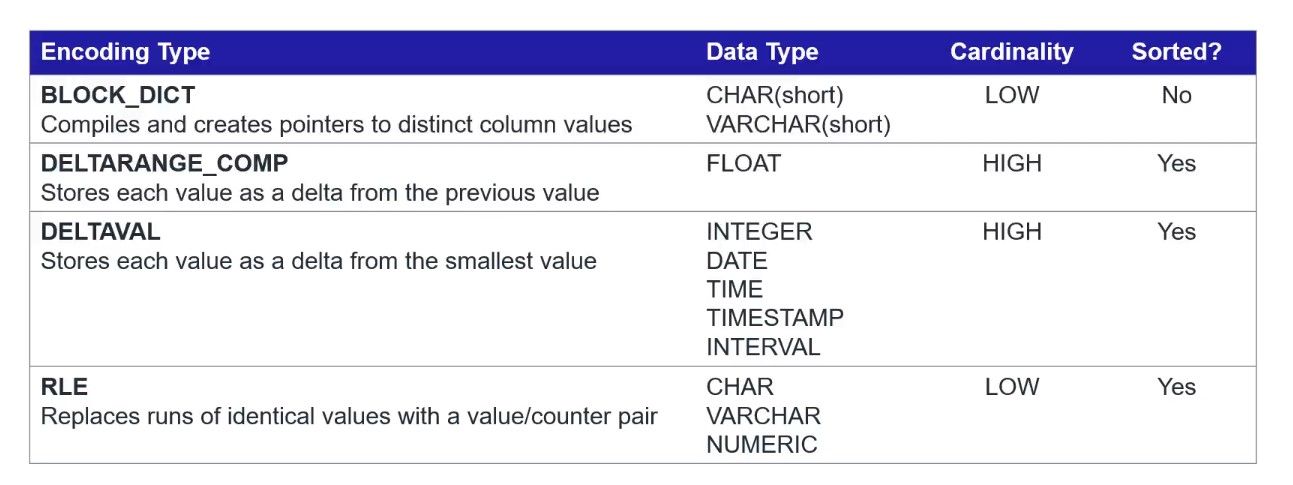
Vertica codifica y comprime agresivamente los datos almacenados en el disco. Esto permite que los datos se almacenen de forma más eficiente y reduce la huella de almacenamiento total, sustituyendo las IO más lentas del disco por ciclos de CPU más rápidos. El método de codificación apropiado para los datos se determina en base al tipo de datos, la cardinalidad de los datos y si los datos han sido clasificados. En la siguiente tabla podemos apreciar una selección de los métodos de codificación disponibles.
4. Consola de administración
La Consola de Administración o MC, es la herramienta de control y gestión de Vertica, accesible a través de un navegador web. Su interfaz gráfica de usuario proporciona una visión unificada de las operaciones de la base de datos de Vertica. A través de pantallas paso a paso fáciles de usar, puede crear, configurar, gestionar y supervisar sus bases de datos Vertica y sus grupos asociados. Ejemplos de tareas de la Consola de Gestión incluyen:
- Crear y gestionar múltiples bases de datos y clusters desde un único punto de control.
- Configuración de los parámetros de la base de datos y de los ajustes del usuario.
- Supervisión del uso y la conformidad de la licencia.
- Supervisión de la carga de datos y del rendimiento de las consultas.
- Recepción de alertas del sistema basadas en disparadores configurables.
- Ejecución de diagnósticos de la base de datos.
5. Enterprise y Eon mode
Vertica tiene dos modos de despliegue. El modo Enterprise y el modo Eon, cada uno de esos modos de despliegue puede ser instalado tanto en máquinas privadas como en cualquiera de las principales nubes públicas (Amazon AWS, la nube de Google o Microsoft Azure).
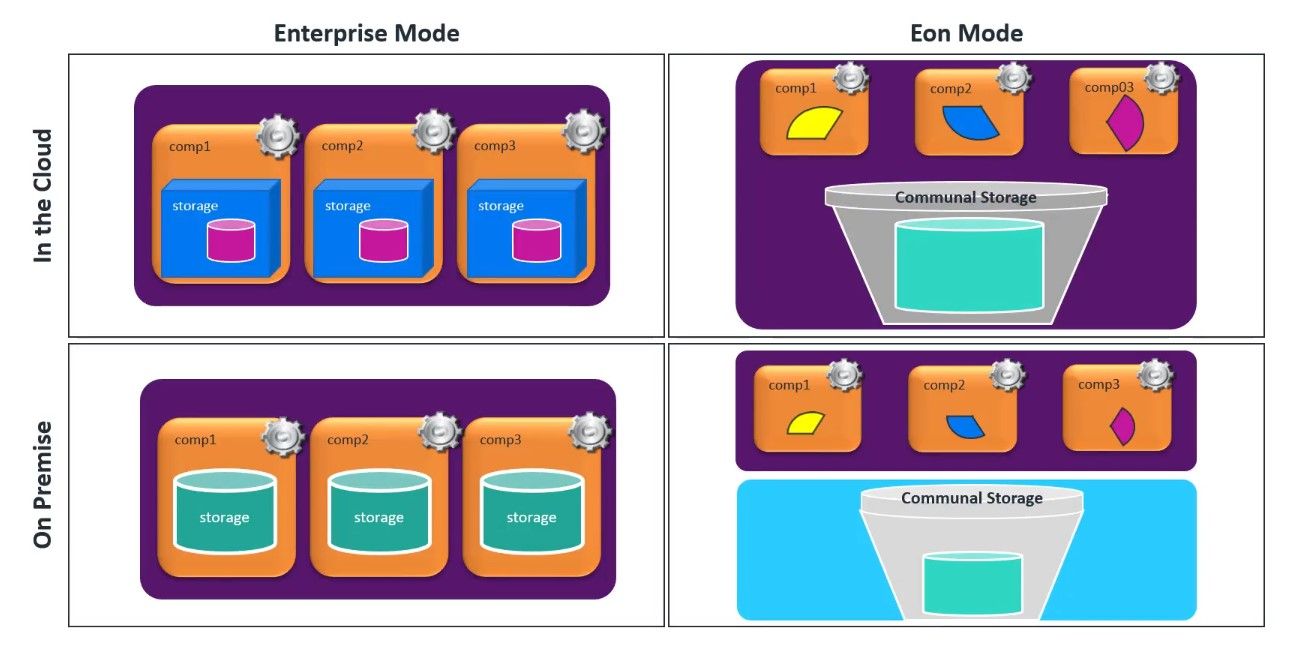
En un despliegue Enterprise estándar, el almacenamiento de la base de datos y el procesamiento computacional son controlados por el mismo nodo, ya sea que su despliegue esté alojado en la nube o en las instalaciones. A medida que estas necesidades cambian, la única manera de aumentar o disminuir estas capacidades, es añadir o eliminar nodos de su clúster.
Usando Vertica en modo Eon, puedes aprovechar la economía de la arquitectura separando la funcionalidad del ordenador y del almacenamiento. En modo Eon, la base de datos se almacena en un lugar de almacenamiento común. Ya sea en su entorno de nube o en una ubicación en una zona de memoria concreta. En cualquiera de los casos, la base de datos se divide en fragmentos a los que se suscriben los nodos computacionales. Estos nodos realizan cualquier función de cálculo en los datos locales de cada nodo. Todos los fragmentos deben estar suscritos por los nodos para que las consultas puedan ser procesadas. Usando esta funcionalidad se pueden hacer girar nodos adicionales para acomodar el aumento de la carga de trabajo. Puede añadir o eliminar rápidamente nodos a su clúster y, opcionalmente, a los nodos de subclústeres relacionados con la tarea.
6. Fiabilidad y escalabilidad
Vertica en modo Enterprise se ejecuta en computadoras y dispositivos de almacenamiento estándar el sistema operativo Linux. No requiere una construcción especial de los servidores y utiliza la sintaxis estándar ANSI SQL para las consultas. La base de datos distribuida de Vertica, está diseñada para trabajar en clusters de servidores y listos para usar, y su rendimiento se escala simplemente añadiendo nuevos servidores al clúster. También vale la pena señalar que Vertica puede ser incrustada y ejecutada en un solo nodo también.
El Procesamiento Masivo Paralelo, o MPP, permite que todos los nodos participen por igual en el procesamiento de la base de datos. Las consultas tendrán acceso a los recursos de todos los nodos del grupo. Esto también evita tener un único punto de fallo si los nodos no están disponibles.
Vertica incluye un equilibrador de carga de software interno. Cuando se envía una consulta o se cargan datos, podemos distribuir la carga de trabajo entre todos los nodos del clúster. Además puede implementar un equilibrador de carga externo para distribuir las entradas al clúster de Vertica, de modo que ningún nodo sea responsable de iniciar las tareas. Es muy recomendable separar el ancho de banda, usando redes privadas y de clientes.
La red de clientes se utiliza para la comunicación dentro y fuera de Vertica. Consultas, carga de datos, herramientas de informes, etc. La red privada se utiliza para la comunicación entre los nodos de Vertica. Lo ideal sería que sólo los planes de consulta, los resultados de las consultas y las cargas de datos viajaran a través de la red privada.
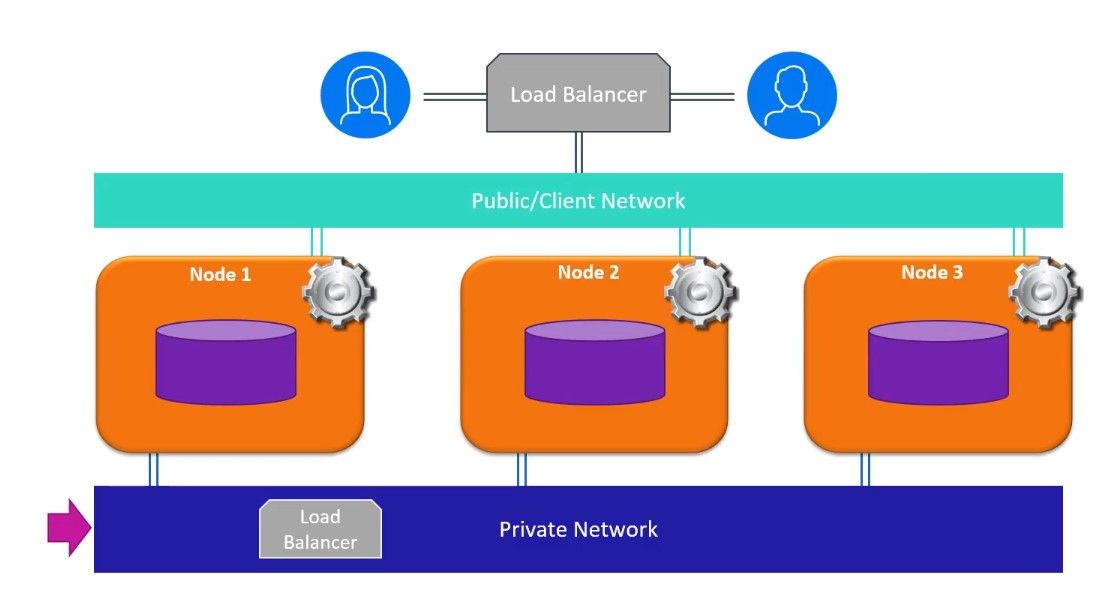
Vertica en modo Eon implementa un procesamiento masivo en paralelo de manera similar, pero cada nodo en lugar de disponer de una memoria local dedicada, la base de datos existe en un lugar de almacenamiento compartido, por ejemplo, un cubo S3. Esto permite agregar, eliminar y agrupar la potencia de cálculo independientemente del espacio de disco necesario para almacenar los datos.
Vertica mantiene la accesibilidad de los datos si un nodo no está disponible, guardando una copia de esos datos en los nodos vecinos. Los datos pueden seguir siendo cargados en la base de datos y las consultas pueden seguir ejecutándose hasta que el nodo vuelva a estar disponible y se recupere la base de datos.
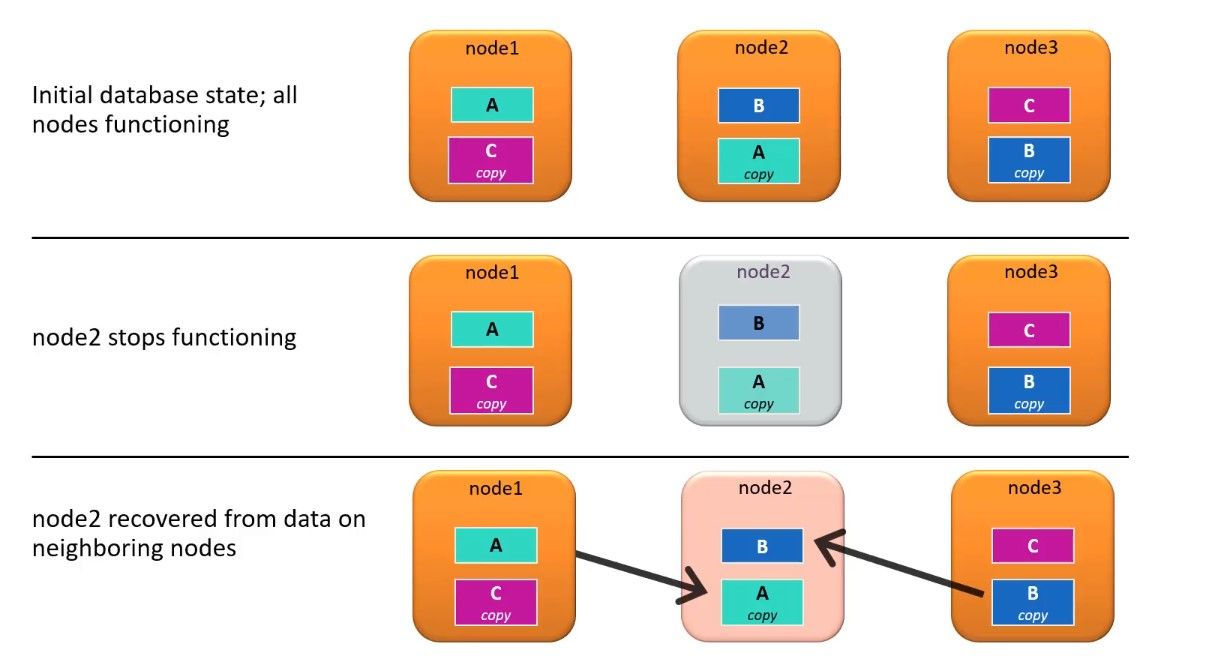
En este grupo de nodos de muestra, se almacenan subconjuntos distribuidos uniformemente de todos los datos en cada nodo y se guardan copias de los subconjuntos en los nodos vecinos. Si el nodo dos deja de funcionar, la base de datos sigue siendo accesible porque los datos están disponibles en los nodos vecinos. Cuando se recupera el nodo dos, cualquier cambio en los datos que se almacenaron en los nodos uno y tres se recupera automáticamente en el nodo dos y la base de datos vuelve a ser estable.
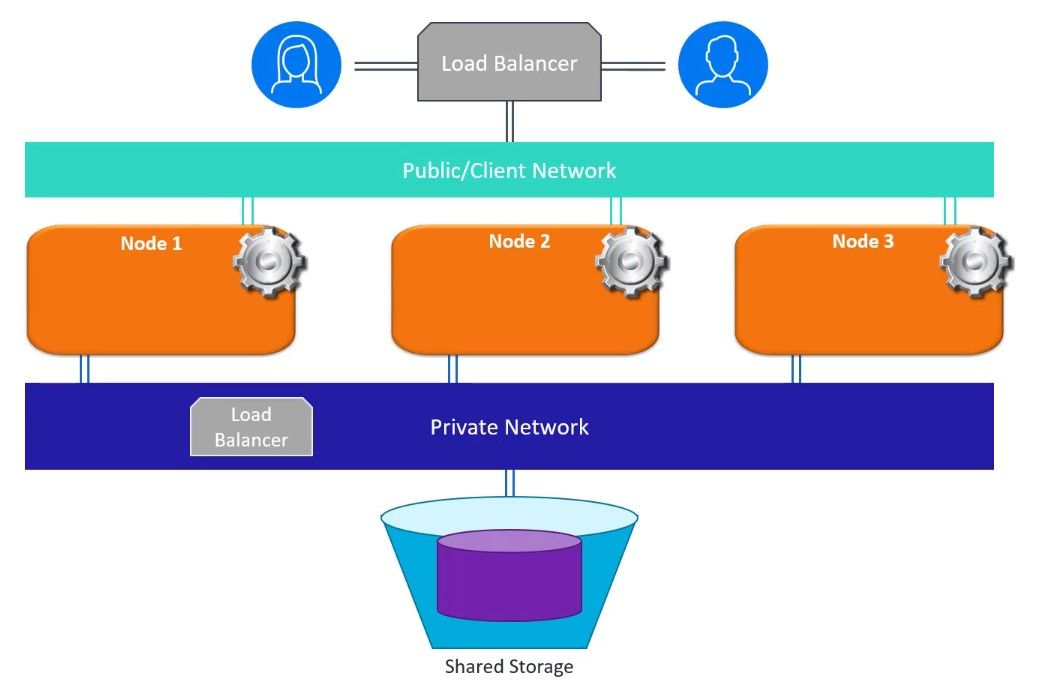
En el modo Eon, los datos están contenidos en una ubicación de almacenamiento compartida y el trabajo de ejecución es realizado por uno o más nodos. Los motores de optimización y ejecución de Vertica funcionan en estos nodos.
Pero ¿cómo saben estos nodos en qué datos deben realizar las operaciones? Cada nodo se suscribe a uno o más fragmentos. Esto permite la distribución de la potencia de procesamiento, para que ningún nodo se sobrecargue. En este escenario, si un nodo no está disponible, toda la base de datos tampoco lo estará. Para asegurar una alta disponibilidad, cada nodo también se suscribe a un fragmento secundario, que tiene datos que se ejecutan en otro nodo, por lo que la base de datos puede seguir funcionando hasta que se restaure el nodo no disponible.