


1. Novedades Pdi 9.0
Las principales novedades de PDI 9.0 son las siguientes:
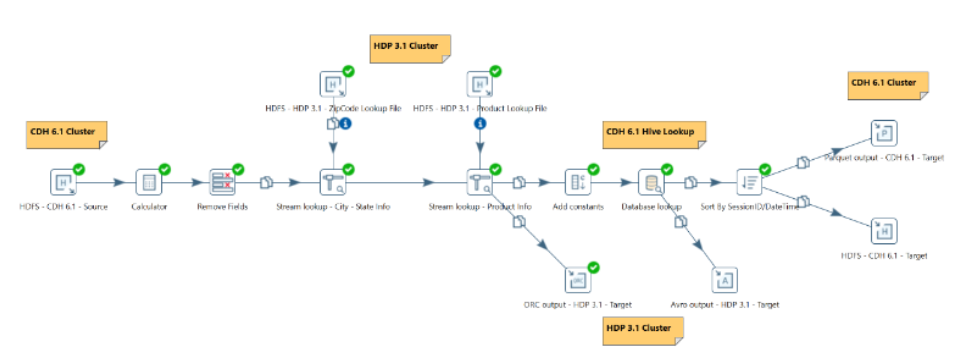
- Los usuarios pueden acceder y procesar datos de múltiples clústeres de Hadoop, de diferentes distribuciones y versiones, todo desde una sola transformación e instancia de Pentaho.
- Además, dentro de Spoon, los usuarios ahora pueden configurar tres configuraciones distintas de clúster, todas con referencia a un clúster específico, sin tener que reiniciar Spoon.
- La nueva interfaz de usuario brinda una experiencia mejorada para la configuración de clústeres y para la creación de conexiones seguras.
- Admite las siguientes distribuciones: Hortonworks HDP v3.0, 3.1; Cloudera CDH v6.1, 6.2; Amazon EMR v5.21, 5.24.
El siguiente ejemplo muestra un Multi-clúster implementado sobre el mismo pipeline de datos con conexión a los clústeres Hortonworks HDP y Cloudera CDH.
Casos de uso y beneficios
· Permite el procesamiento de Big Data híbrido (local o en la nube), dentro de un mismo pipeline de procesamiento de datos.
· Simplifica la integración de Pentaho con clústeres de Hadoop, mediante una experiencia de usuario mejorada para configuraciones de clúster.
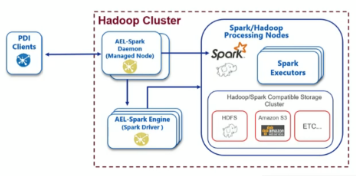
Pentaho Adaptive Execution Layer (AEL) está diseñada para proporcionar un procesamiento de datos más flexible al permitir la utilización del motor de Spark además del motor nativo de Kettle. Esto permite utilizar el motor de Spark con la Interfaz de PDI sin necesidad de código. Soporta las versiones 2.3 y 2.4 de Spark.
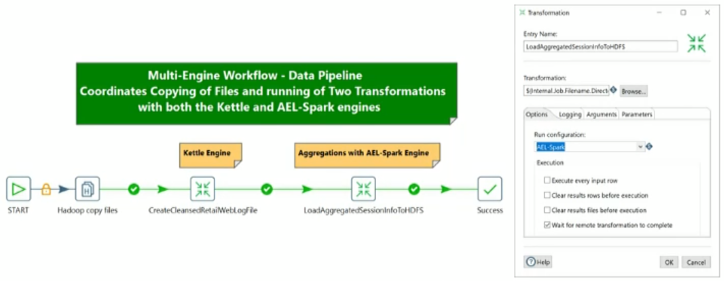
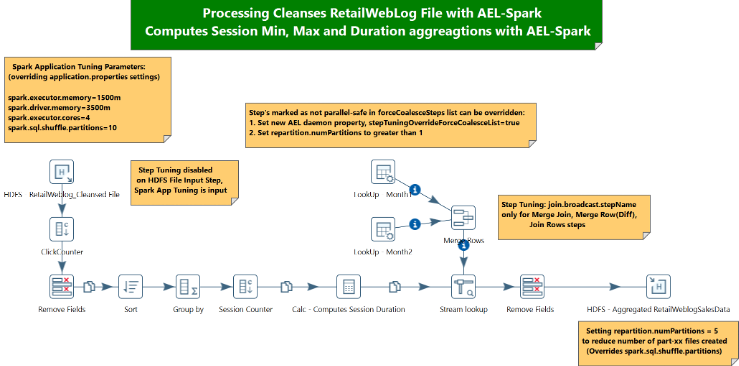
Casos de uso y beneficios
· Elimina la utilización de código propia de Spark y añade una mejor visualización.
· Permite a los usuarios avanzados de Spark utilizar herramientas para mejorar su rendimiento.
Los cambios del Virtual File System (VFS) se encuentran en dos áreas principales:
Agrega conexiones VFS para Amazon S3 y Snowflake Staging, e introduce Pentaho VFS (PVFS) para definir distintas conexiones VFS y sus protocolos.
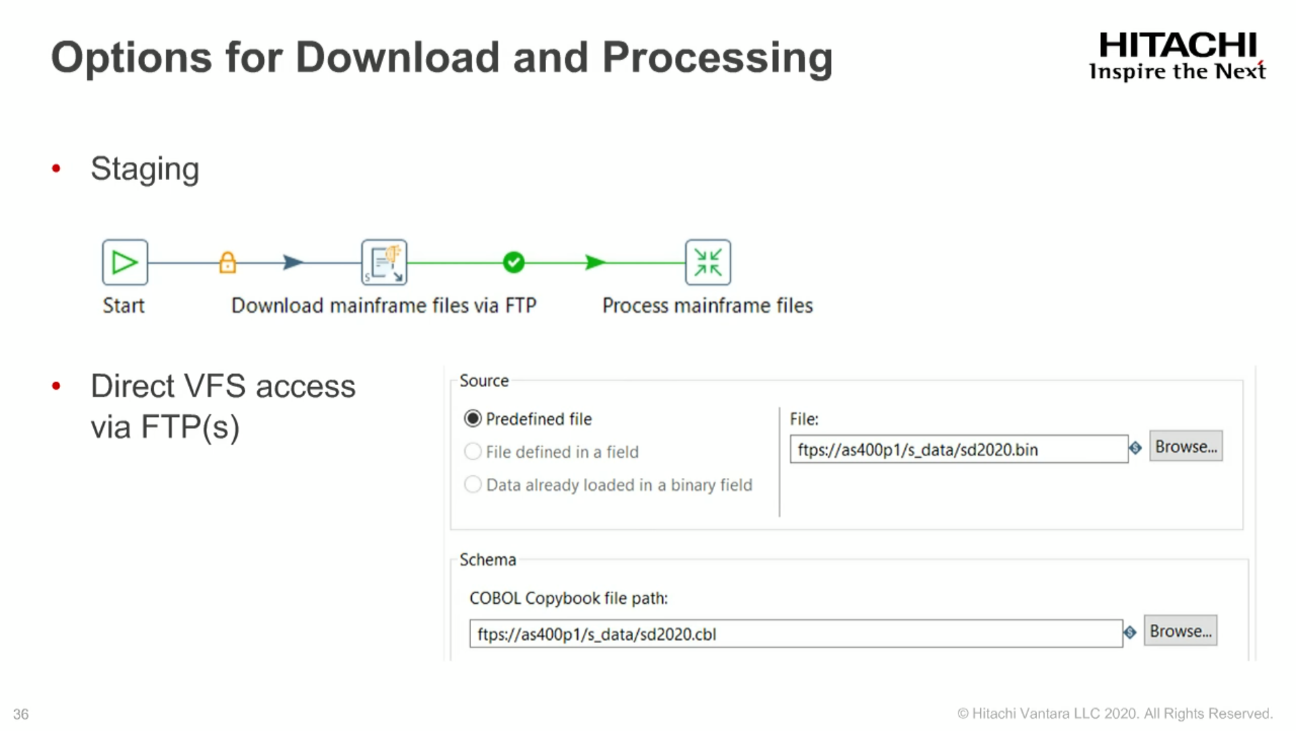
Incorporación de un navegador VFS que te permite localizar cualquier VFS ya preconfigurada.
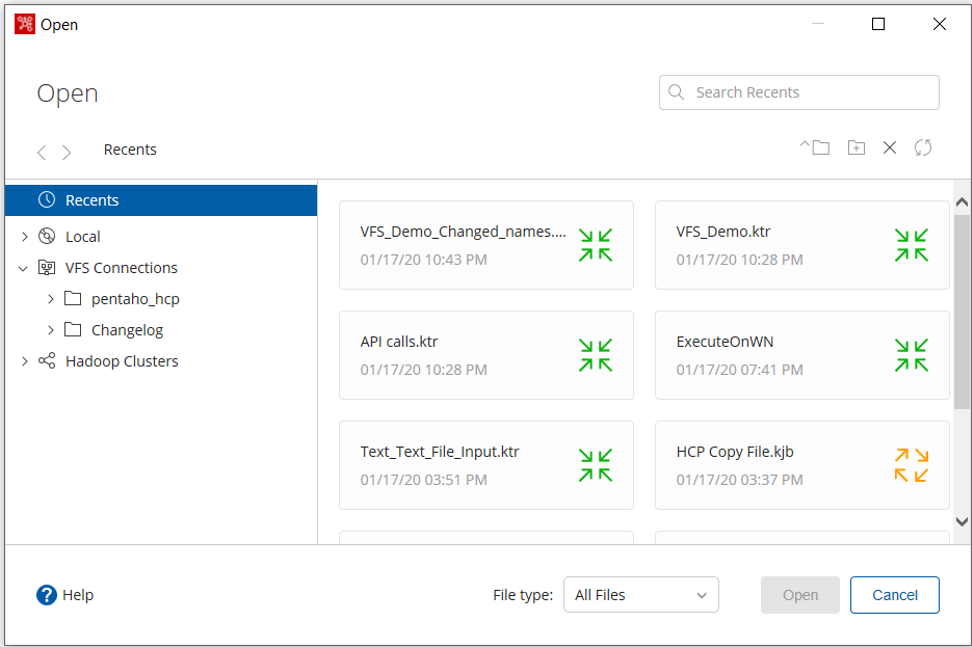
Casos de uso y beneficios
· Con Pentaho VFS se obtiene una abstracción del protocolo. Eso significa que cuando una empresa desee cambiar al proveedor de almacenamiento en el futuro, todos los jobs y trasformaciones funcionarán con un mínimo de problemas.
· El conector VFS permite ahora usar diferentes cuentas y servidores dentro de una transformación PDI.
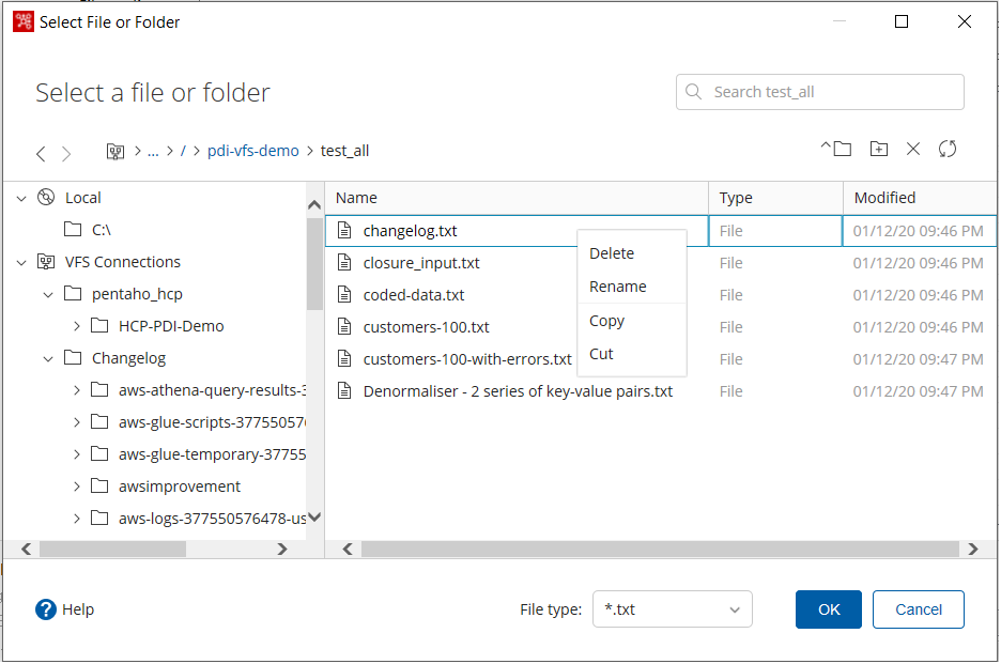
El navegador VFS te permite manejar de manera más eficiente los archivos de ubicaciones remotas, ampliando el alcance de PDI. Por ejemplo, un usuario puede copiar archivos de Google Cloud a un almacén S3 utilizando la función de copiar y pegar del navegador.
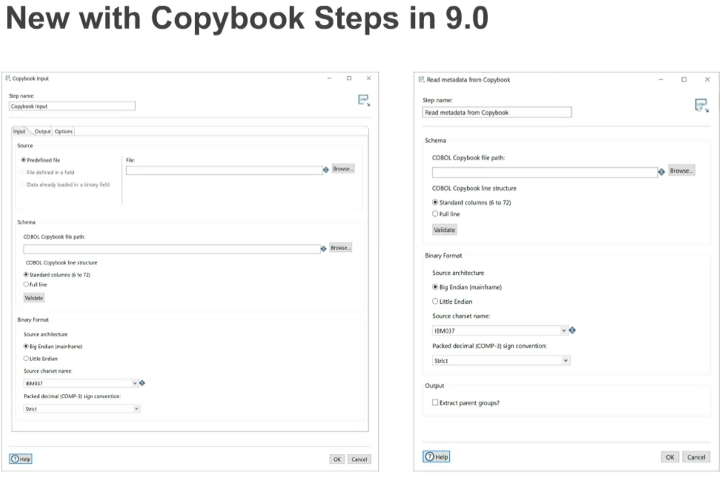
PDI ahora tiene dos nuevas transformaciones que se pueden usar para leer registros desde un mainframe de COBOL y transfórmalos en filas de PDI.
· Copybook Input: este paso permite leer los archivos de datos binarios de un mainframe mediante definiciones de Copybook y permite usar los datos en las transformaciones de PDI.
· Leer metadatos desde Copybook: este paso permite leer metadatos desde el archivo de definición de Copybook para usarlos con ETL Metadata Injection en PDI.
Los pasos del Copybook también permiten introducir metadatos, manejo extendido de errores y puede funcionar con redefiniciones.
Casos de uso y beneficios
PDI admite la integración con los registros de longitud fija de datos binarios de un mainframe de COBOL para que cualquier usuario pueda utilizar, integrar y combinar esos datos como parte de su pipeline. Esta capacidad es crítica cuando una empresa posee grandes cantidades de conjuntos de datos transaccionales de clientes y se requiere hacer búsquedas y queries para crear reportes.
· Nuevo Pentaho Server Upgrade Installer: Es una interfaz gráfica de usuario (GUI) que instala automáticamente una nueva versión dentro del archivo de instalación del Pentaho Server. Esto permite hacer upgradedesde las versiones 7.1 en adelante directamente a la versión 9.0.
· Mejoras en Snowflake Bulk Loader: Ahora se permite hacer la vista previa de una tabla de Snowflake en PDI 9.0. El usuario puede ver el diseño de columnas esperado y los tipos de datos y hacer match con el archivo de datos.
· Soporte de seguridad de Redshift IAM y mejoras de carga masiva: Esta versión incluye más opciones de autentificación contra bases de datos Redshift.
· Mejoras en Bulk Load en Amazon Redshift: La nueva edición tiene nuevas pestañas de opciones y columnas en la Salida de Bulk Load dentro de PDI Amazon Redshift.
· Mejoras en los cambios de AMQP y UX en Kinesis: El paso AMQP Consumer proporciona soporte de mensajes binarios, por ejemplo, permite procesar datos con formato de esquemas AVRO. Dentro del paso Kinesis Consumer, los usuarios pueden cambiar los nombres y tipos de los campos de salida.
· Mejoras en Metadata Injection (MDI): PDI 9.0 continúa habilitando más pasos para admitir la inyección de metadatos (MDI), permitiendo dividir campos en filas, eliminar campos y realizar operaciones en strings.
· Excel Writer: En el paso Excel Writer, se agregó un MDI Step, “Comenzar a escribir en la celda”. Además, el rendimiento se ha mejorado drásticamente cuando se utilizan plantillas.
· Cambios de JMS Consumer: Se agregaron los siguientes campos al paso JMS Consumer: MessageID, JMS timestamp y JMS Redelivered.
· Text File Output: ahora soporta la opción de Header con AEL, esto permite configurar el paso Text File Input para que se ejecute en el motor Spark a través de AEL.
· Pasos y entradas de Transformaciones y Jobs: Antes, al pasar parámetros a transformaciones/jobs, las opciones de “Stream column name” y “Value” (“Field to us” y “Static input value”) eran ambiguas y generaban problemas difíciles de identificar. En la edición 9.0, se agregó un comportamiento que impide que un usuario ingrese valores en ambos campos para evitar estas situaciones.
· Mejoras en los logs de salida de Spoon.sh: Spoon.sh (cuando es llamado por kitchen.sh o pan.sh) envía el estado de salida incorrecto en ciertas situaciones. En la versión 9.0, se agregó una nueva variable de entorno FILTER_GTK_WARNINGS para poder controlar este comportamiento. Esta componente permite aplicar un filtro para ignorar cualquier advertencia de GTK. Si no desea filtrar ninguna advertencia, se desactiva.
· Mejoras en Analyzer: Ahora se puede mostrar los totales de las columnas en la parte superior y los totales de las filas a la izquierda de los informes de Analyzer.
Opción para exportar reportes de Analyzer a formato CSV: Ahora se puede exportar informes de Analyzer como PDF, CSV o libros de Excel.
2. Versionado
Antes de nada, comentar que esta funcionalidad también está incluida en PDI 8.2.
PDI se puede apoyar en Pentaho BA Server, en casi cualquier base de datos externar o en un sistema de ficheros como repositorio.
En este documento se va a comprobar el funcionamiento del repositorio de Pentaho Server con la función de versionado.
Para activar el versionado del repositorio de Pentaho Server hay que modificar con un editor de texto el siguiente archivo:
\pentaho-server-ce-9.0.0.0-423\pentaho-server\pentaho-solutions\system\repository.spring.xml
Y cambiar las siguientes líneas:
<bean class="java.lang.Boolean" id="versioningEnabled=true">
<bean class="java.lang.Boolean" id="versionCommentsEnabled=true">
Esta última línea sirve para poder añadir un comentario a cada nueva versión que se cree.
Se puede obtener más información sobre como activar/desactivar el versionado en este enlace.
Una vez modificado el archivo se deja ejecutando Pentaho Server y se conecta a su repositorio dentro de PDI:
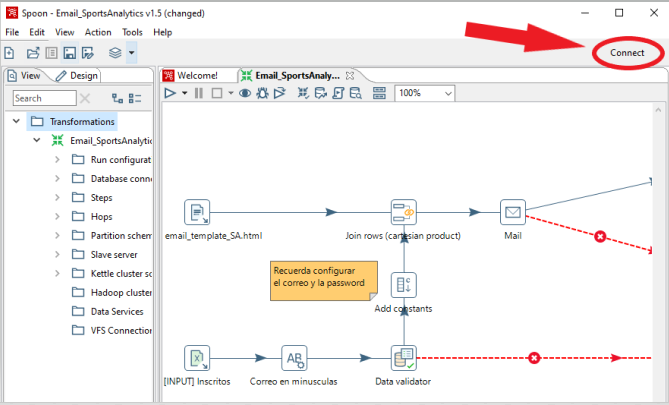
Se abrirá una pestaña y para configurar el repositorio de Pentaho Server hay que pinchar en Get Started y añadir sus datos.
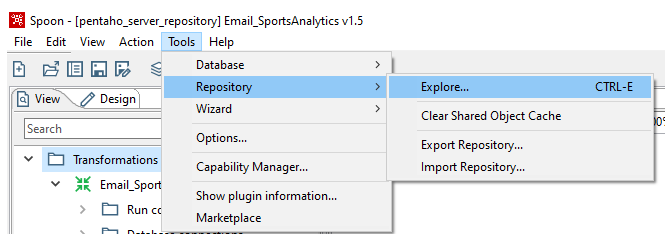
Para comprobar que el versionado esta activado correctamente, dentro de PDI hay que ir a la pestaña de Tools > Repository > Explore…:
Y comprobar que aparece la pestaña de Version History:
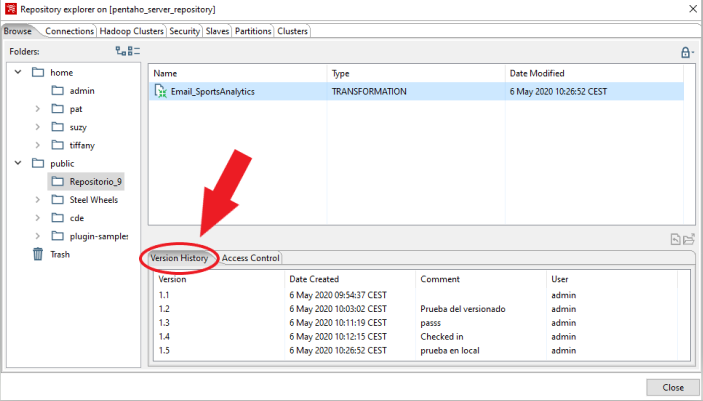
Para abrir una versión hay que darle click derecho a la versión que se quiere abrir y a Open.
Tras varias pruebas, la herramienta carga correctamente las distintas versiones de las transformaciones o jobs creados.
3. Carte
Esta funcionalidad también existe en versiones anteriores de PDI 9.0.
Según la propia definición de Pentaho: “Carte es un servidor web simple que le permite ejecutar transformaciones y trabajos de forma remota. Lo hace aceptando XML (usando un pequeño servlet) que contiene la transformación a ejecutar y la configuración de ejecución. También le permite monitorear, iniciar y detener de forma remota las transformaciones y trabajos que se ejecutan en el servidor Carte. Un servidor que ejecuta Carte se llama Servidor Esclavo en la terminología de Pentaho Data Integration.”
La herramienta ofrece las mismas capacidades que puede ofrecer Pentaho Server, pero sin sistema de gestión de archivos, calendario y administración de seguridad.
Pasos previos:
· Instalar Java Runtime Environment (JRE) versión 1.5 o mayor.
· Añadir la variable de entorno JAVA_HOME.
Para configurar un servidor se debe crear un fichero configuration.xml y guardarlo en el directorio de PDI (pdi-ce-X/data-integration/) con la siguiente estructura:
<slave_config>
<slaveserver>
<name>Master</name>
<hostname>localhost</hostname>
<port>9001</port>
<username>carte</username>
<password>carte</password>
</slaveserver>
<max_log_lines>10000</max_log_lines>
<max_log_timeout_minutes>1440</max_log_timeout_minutes>
<object_timeout_minutes>1440</object_timeout_minutes>
</slave_config>
Ejecutar en la cmd el siguiente comando:
Carte.bat configuration.xml
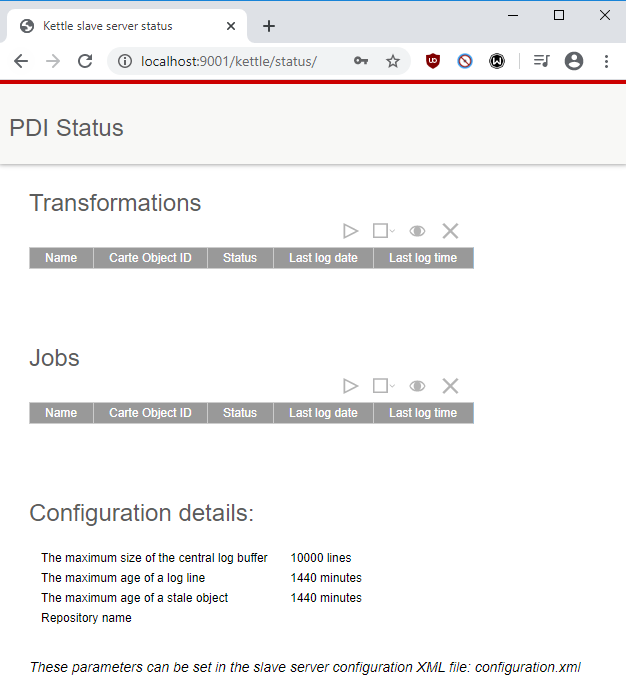
Una vez se ejecute y para hacer seguimiento de los procesos ETL se puede acceder desde el navegador al menú de Carte, en este caso con la dirección localhost:9001, donde saldrá una ventana como la siguiente, en la cual se puede observar el estado de los jobs/transformaciones y la configuración de Carte:
Para ejecutar una transformación desde el navegador se debe introducir el siguiente enlace donde esta contenido la ruta de la transformación a ejecutar: (ejemplo)
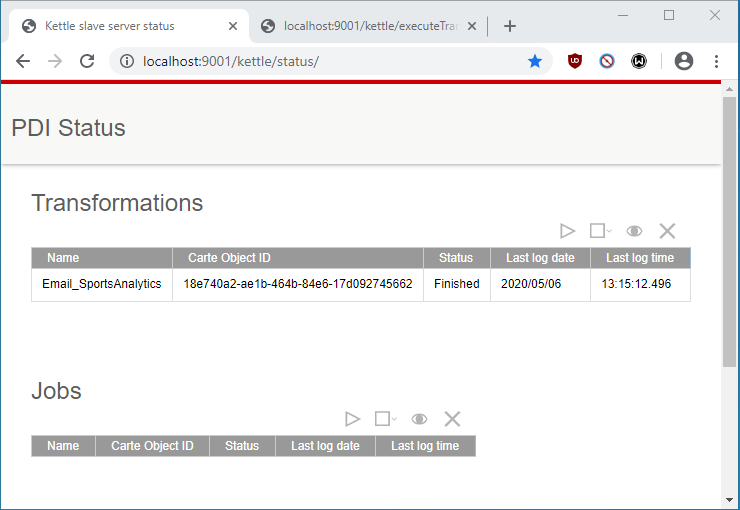
Tras ejecutar esta transformación podemos observar su estado en el menú de Carte:
Carte, además, permite la creación de un Clúster entre dos o más Servidores Esclavos y un Servidor Maestro. Cuando se ejecuta una transformación, las diferentes partes de esta se procesan a través de los Servidores Esclavos, mientras que el Servidor Master hace un seguimiento del proceso. Esto permite aumentar la velocidad con la que se procesan las transformaciones.
Para crear un Clúster con Carte viene todo el proceso bien explicado en este enlacedel propio Pentaho.