

So... What's new then?
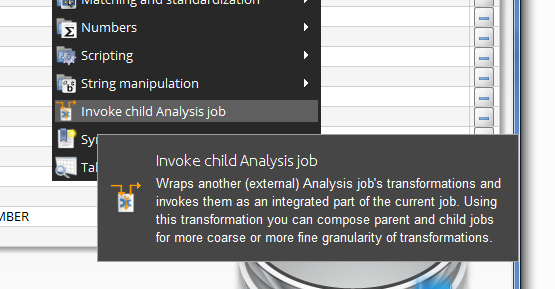
- You can now compose jobs so that a DataCleaner job actually calls/invokes another "child" job as a single transformation. This is an important feature because it allows users to organize and compose complex data processing flows into smaller chunks of work. The new "Invoke child Analysis Job" transformation inlines the transformation section of the child job at execution time, which means that there is practically no overhead to this approach.
- As a convenience for the above scenario, it is now allowed to save jobs without any analysis section in them. These jobs will thus be "incomplete", but that might actually be the point when composing and putting jobs together.
- Another new transformation was added: Coalesce multiple fields. This transformation is useful for scenarios where multiple sets of fields are interchangeable, or when multiple interchangeable transformations produce the same set of fields. The "coalesce" transformation can roughly be translated into "pick the first non-empty values". When there's multiple sets of fields in your data processing stream, for instance multiple address definitions, and you need to select just one, then this is very convenient.
- The handling of source columns has been simplified. Previously we tried to limit the source queries based upon only the source columns that where strictly needed to perform the analysis. But many users gave us the feedback that this caused trouble because the drill-to-detail information available in the analysis results would then be missing important fields for further exploration. So the power is now in the hands of the users: The fields added in the "Source" section of the job are the fields that will be queried.
- A change was made to the execution engine in dealing with complex filtering and requirement configurations. Previously, if a component (transformation or analysis) consumed inputs from other components, ALL requirements had to be satisfied, which mostly just causes the requirement to never become true. Now the logic has been changed to be inclusive so that if any of the direct input sources' requirements are satisfied, then the component's inferred requirement is also satisfied. Most users will not notice this change, but it does mean that it is now possible to merge separate filtered data streams back into a single stream.
- An issue was fixed in the access to repository files. Read/write locking is now in place which avoids access conflicts by different processes.
- The 'requirement' button in DataCleaner has also been reworked. It did not always properly respond to changes in other panels, but now it is consistent.
- Finally, the 'About' dialog was improved slightly and now contains more licensing information :-)
We hope you will enjoy this release of DataCleaner. Head over to the downloads page and get your copy now.