

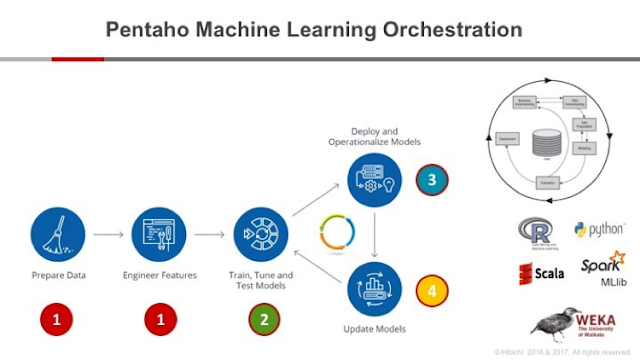

También os hablábamos de como habían introducido el concepto de Machine Intelligence
Hoy, vamos un paso más allá y tras la celebración del reciente evento HitachiNext, en donde se dieron una pinceladas muy interesantes en lo que respecta a como Pentaho facilita y ayuda al uso de Machine Learning y que os resumimos a continuación
1) Integracion con Jupyter Notebooks (novedades Jupyter en PDI -Kettle-)
Hace poco os contábamos y mostrábamos en un video como poder usar Jupyter para nuestros proyectos de Machine Learning
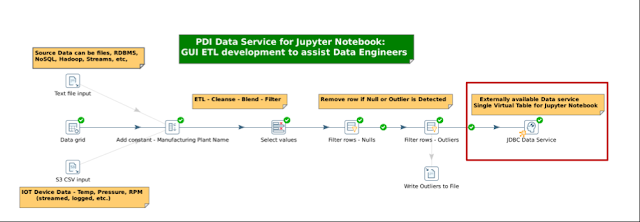
Pentaho ha introducido una mejora para que los ingenieros de datos accedan, limpien, integren y entreguen datos como un servicio para que los científicos de datos los utilicen.
En lugar de crear y mantener manualmente scripts únicos para acceder, modificar y entregar los outputs de datos, los científicos de datos ahora pueden concentrarse en la parte más intelectualmente gratificante de sus trabajos: la exploración de modelos.
Pueden concentrarse en desarrollar análisis perspicaces y precisos en el IDE familiar de un cuaderno Jupyter, una herramienta muy potente y popular para la ciencia contemporánea de datos, y dejar la preparación e integración de datos a los ingenieros de datos.
Al usar la interfaz de arrastrar y soltar en Pentaho Data Integration (PDI), los ingenieros de datos pueden crear transformaciones que resulten en fuentes de datos gobernadas que pueden registrar en un data mart para promover la reutilización entre los equipos de ingeniería de datos y ciencia de datos, lo que fomenta una relación de trabajo más colaborativa.
En esta imagen se ve el step:
2) Orchestrating TensorFlow y Keras
Aunque los ingenieros de datos tienen un profundo conocimiento y experiencia en el almacenamiento de datos, tecnologías SQL, NoSQL y Hadoop, en la mayoría de los casos no tienen las habilidades de codificación de Python o R.
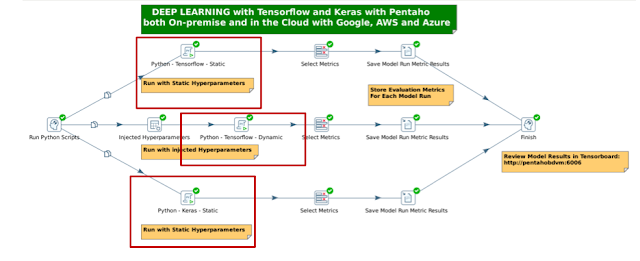
Lo más probable es que no tengan las habilidades matemáticas y estadísticas avanzadas requeridas para ajustar el aprendizaje automático y los modelos de aprendizaje profundo para obtener los modelos más precisos en producción más rápido.
Por ello, se ha añadido un paso que facilita a los Data Scientist ejecutar Machine Learning de forma sencilla
3) Mejora del trabajo con modelos
Normalmente, los modelos se degradan en precisión tan pronto como llegan a los datos de producción.
Se ha introducido un nuevo paso de ejecución de Python, y los usuarios pueden realizar actualizaciones a los modelos utilizando datos de producción.
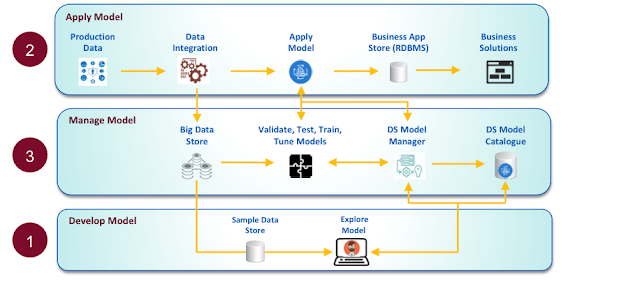
Los ingenieros de datos pueden obtener información sobre el uso del modelo, ejecutar pruebas, revisar las estadísticas de precisión del modelo e intercambiar fácilmente los modelos con la mayor precisión. Al mantener los modelos más precisos en producción, será más fácil tomar mejores decisiones y reducir el riesgo de equivocación
Saber más? el equipo de Stratebi podrá ayudarte