

Hace poco os hablámos sobre las 'Top real-time and best performance analytics tools (open source/free)'
 Emilio
Emilio
En TodoBI, con la ayuda de nuestros amigos y grandes especialistas en todo este tipo de herramientas y proyectos de datos (real time, near real time y con grandes volúmenes), Stratebi, nos proporcionan ahora una comparativa-benchmark de resultado de tiempos de respuesta entre alguna de las bases de datos analyticas planteadas.
Si quieres ver también comparativas y benchmarks con Apache Kylin, Vertica, PostgreSQL, etc... aquí lo tienes:
Admin
1. Introducción a CitusData
Citus es una extensión de código abierto para PostgreSQL que distribuye los datos y las consultas a través de múltiples nodos en un clúster. Citus transforma PostgreSQL en una base de datos distribuida con características como sharding, tablas de referencia y tablas distribuidas.
Citus se escala horizontalmente añadiendo nodos workers y verticalmente actualizando los trabajadores.
Algunas de las ventajas de Citus para las aplicaciones multi-tenant son:
· Consultas rápidas para todos los tenant
· Fragmentación en la base de datos
· Mantenimiento de más datos que los que se pueden mantener en PostgreSQL en un solo nodo
· Escala con SQL fácilmente para manejar las inscripciones de nuevos clientes
Citus admite consultas en tiempo real sobre grandes conjuntos de datos. Las ventajas de Citus en este caso son su capacidad para paralelizar la ejecución de consultas y escalar linealmente con el número de bases de datos de trabajadores en un clúster.
Algunas ventajas de Citus para aplicaciones en tiempo real son las siguientes:
· Mantener respuestas de menos de un segundo con un gran volumen de datos
· Analizar nuevos eventos y datos en tiempo real
· Paralelizar las consultas SQL y ampliar la escala con SQL
· Mantener el rendimiento con una alta concurrencia
· Ofrecer respuestas rápidas a las consultas del cuadro de mandos
A continuación se muestra una imagen de la arquitectura de Citus.

Una base de datos distribuida Citus consta de un nodo coordinador y nodos workers (al menos tiene que haber dos).
Cada nodo es un servidor PostgreSQL con la extensión Citus instalada. El coordinador de Citus organiza las consultas de PostgreSQL para el nodo worker adecuado, y en los workers se encuentran los datos reales y se realiza el cálculo. Las consultas se dirigen a un solo nodo worker y se ejecutan en tablas/índices más pequeños (llamados shards) o se paralelizan entre los nodos workers.
2. Uso de CitusData
Todas las operaciones que se pueden realizar sobre una base de datos se pueden escribir con comandos estándar de PostgreSQL.
Crear tablas
CREATE TABLE nombre_tabla (
columna1 tipo_dato,
columna2 tipo_dato,
...,
);
Crear claves primarias
ALTER TABLE nombre_tabla ADD PRIMARY KEY (PK1, PK2, ...);
Crear índices
CREATE INDEX nombre_índice ON tabla (columna);
Crear tablas de distribución: se debe especificar la tabla que se quiere fragmentar y la columna por la que se va a fragmentar:
SELECT create_distributed_table('nombre_tabla', 'columna[IM2] ');
Crear tablas referenciadas
SELECT create_reference_table('nombre_tabla');
Cargar datos
\copy nombre_tabla from 'nombre_fichero.csv' with csv
Ejecutar consultas tipo INSERT, UPDATE y DELETE.
INSERT INTO nombre_tabla VALUES (V1, V2, ...);
UPDATE nombre_tabla
SET columna = valor
WHERE condición;
BEGIN;
DELETE FROM columna WHERE condición;
COMMIT;
También se pueden ejecutar consultas analíticas y consultas de tipo join sobre varias tablas utilizando el SQL estándar. Para las consultas de tipo join sobre varias tablas, se debe crear tablas referenciadas sobre las dimensiones.
3. Casos de uso
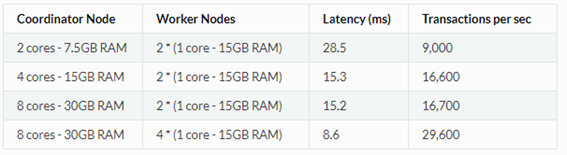
INSERT:Para los resultados de estas pruebas, se ha utilizado la configuración predeterminada y se ha establecido el recuento de hilos concurrentes en 64 y el recuento de clientes en 256.
La primera fila muestra los números de rendimiento para un clúster Citus de nivel básico con dos núcleos físicos como coordinador y dos núcleos físicos como nodos workers. Este clúster básico puede entregar 9000 INSERT por segundo.
En la segunda y tercera fila podemos observar un cuello de botella ya que la tercera fila, aun teniendo el doble de nodos coordinadores que la segunda pero manteniendo el número de los nodos workers, solo se pueden realizar 100 INSERT más.
La tercera fila muestra los datos de un clúster aproximadamente cuatro veces más potente que el de la primera fila y puede realizar 30000 INSERT por segundo .
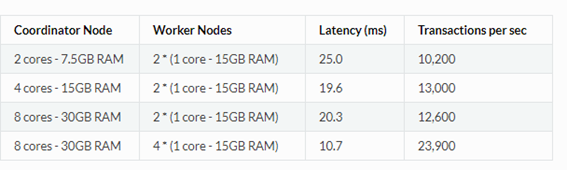
UPDATE:Para medir los rendimientos de UPDATE con Citus, utilizamos los mismos datos que en el caso anterior. Podemos observar que el rendimiento de UPDATE de Citus es ligeramente inferior al de INSERT.
A continuación, vamos a analizar la siguiente consulta utilizando el comando EXPLAIN.
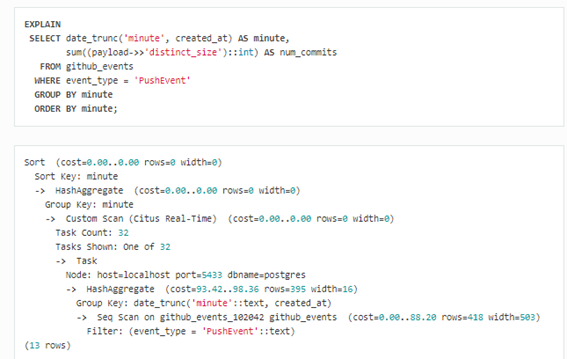
Podemos observar que hay 32 fragmentos y que el planificador ejecuta la consulta en tiempo real.
A continuación, el planificador elige uno de los nodos workers y muestra su host, su puerto y su base de datos.
4. Comparativa CitusData vs Swarm64 vs Clickhouse
Citus es una extensión de PostgreSQL que distribuye los datos y las consultas en un clúster de múltiples máquinas. Su motor de consulta paraleliza las consultas SQL entrantes para permitir respuestas en tiempo real (menos de un segundo) en grandes conjuntos de datos. Fue construido para escalar.
Swarm64 amplía PostgreSQL con mejoras en el motor de consultas, mayor procesamiento en paralelo e indexación columnar comprimida. Rentabiliza el uso y los beneficios de PostgreSQL con un rendimiento de consultas más rápido, especialmente para proyectos que requieren consultas intensivas como generación de informes, almacenamiento y agregación de datos, ETL, etc.
Clickhouse es un sistema gestor de bases de datos orientado a columnas y permite el análisis de datos en tiempo real. Ofrece resultados instantáneos en la mayoría de los casos.
Las ventajas más destacables de Citus son el procesamiento paralelo multinúcleo y su distribución con auto-sharding mientras que entre las ventajas de Swarm64 destacan su concurrencia mejorada, la mayor eficiencia de E/S y memoria, no requiere reestructuración ni migración de datos y permite consultar un gran volumen de datos. Por su parte, las ventajas de Clickhouse son la rapidez, la buena relación de compresión y el escalado horizontal.
A continuación se muestra la comparativa de las tres tecnologías en diferentes aspectos.
Velocidad de consultas pequeñas
· Citusdata (conjunto de datos de 1.1GB)
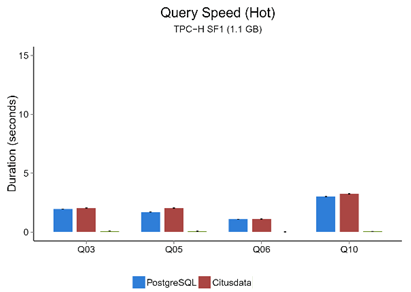
· Clickhouse (Conjunto de datos de 10.000 filas)
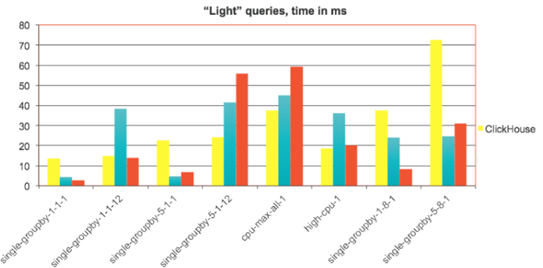
· Swarm64 (conjunto de datos de 1TB utilizando 32 Cores)
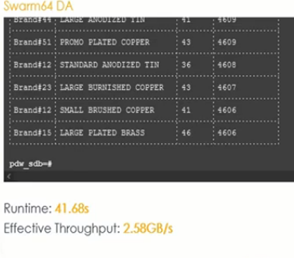
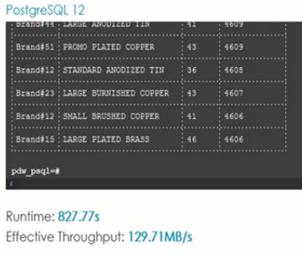
Velocidad de consultas de gran volumen
· Citusdata (conjunto de datos de 11GB)
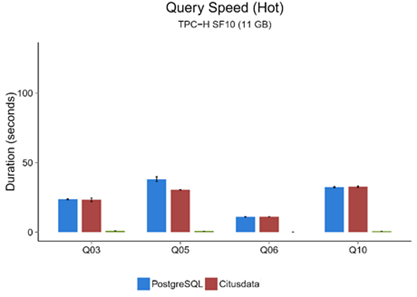
· Clickhouse (conjunto de datos de 85GB)
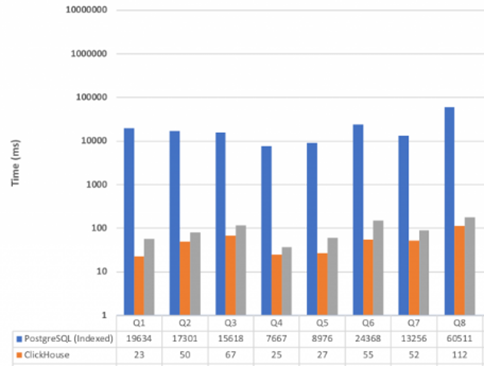
Otro ejemplo del rendimiento de Clickhouse:

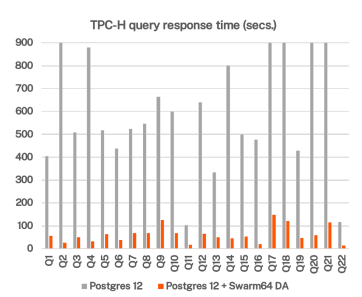
· Swarm64 (conjunto de datos de 1TB)
Precios
· Citusdata: ofrece tres productos: Citus Community (gratuito), Citus on Azure (el precio depende de los servicios usados, consultar tablas) y Citus Enterprise (no se especifica el precio, solicitar presupuesto por correo electrónico).
·
|
TAMAÑO DEL NODO COORDINADOR |
||
|
NÚCLEO VIRTUAL / NODO |
MEMORIA (GB/NODO) |
PRECIO/NODO |
|
4 |
16 GB |
0,474 €/hora |
|
8 |
32 GB |
0,948 €/hora |
|
16 |
64 GB |
1,896 €/hora |
|
32 |
128 GB |
3,792 €/hora |
|
64 |
256 GB |
7,583 €/hora |
|
TAMAÑO DE UN NODO WORKER |
||
|
NÚCLEO VIRTUAL / NODO |
MEMORIA (GB/NODO) |
PRECIO/NODO |
|
4 |
32
GB |
0,605
€/hora |
|
8 |
64
GB |
1,209
€/hora |
|
16 |
128
GB |
2,418
€/hora |
|
32 |
256
GB |
4,836
€/hora |
|
64 |
432
GB |
9,672
€/hora |
|
ALMACENAMIENTO POR NODO |
|
|
ALMACENAMIENTO |
PRECIO |
|
0,5 TB |
59,16 €/mes |
|
1,0 TB |
118,31 €/mes |
|
2,0 TB |
236,61 €/mes |
· Swarm64: ofrece tres productos: Swarm64 DA Development (licencia gratuita durante 1 año), Swarm64 DA Production (33$ por core al mes y existe un plan de 528$ al mes por 16 cores y 128GB de RAM) y Swarm Performance Engineering Suport (1500$ al mes).
· Clickhouse: ofrece un solo producto y es totalmente gratuito.
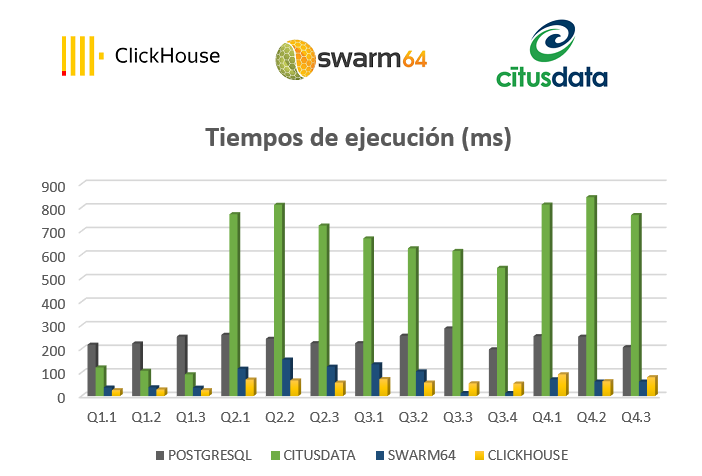
Tiempos de ejecución de diferentes consultas
|
|
POSTGRESQL |
CITUSDATA |
CLICKHOUSE |
SWARM64 |
|
Q1.1 |
218
ms |
121,047
ms |
25 ms |
36,000
ms |
|
Q1.2 |
223 ms |
107,007 ms |
28 ms |
37,086 ms |
|
Q1.3 |
252 ms |
92,230 ms |
25 ms |
35,336 ms |
|
Q2.1 |
260 ms |
771,343 ms |
70 ms |
115,950 ms |
|
Q2.2 |
243 ms |
811,587 ms |
66 ms |
154,640 ms |
|
Q2.3 |
224 ms |
723,482 ms |
57 ms |
124,371 ms |
|
Q3.1 |
224 ms |
668,963 ms |
72 ms |
134,351 ms |
|
Q3.2 |
256 ms |
626,778 ms |
57 ms |
104,461 ms |
|
Q3.3 |
287 ms |
615,616 ms |
54 ms |
12,343 ms |
|
Q3.4 |
198 ms |
543,856 ms |
53 ms |
12,419 ms |
|
Q4.1 |
254 ms |
812,564 ms |
92 ms |
70,819 ms |
|
Q4.2 |
252 ms |
843,716 ms |
63 ms |
61,591 ms |
|
Q4.3 |
207 ms |
767,646 ms |
80 ms |
61,146 ms |
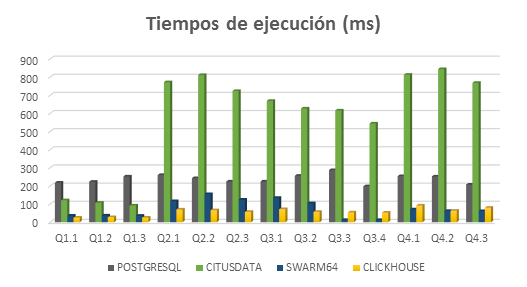
· Q1.1, Q1.2 y Q1.3: se procesan 202.910 filas y se obtiene 1 fila resultado.
· Q2.1, Q2.2 y Q2.3: se procesan 223.110 filas y se obtienen 274, 55 Y 7 filas resultado, respectivamente.
· Q3.1, Q3.2, Q3.3 y Q3.4: se procesan 206.110 filas y se obtienen 150, 145, 0 y 0 filas resultado, respectivamente.
· Q4.1, Q4.2 y Q4.3: se procesan 226.110 filas y se obtienen 35, 98 y 19 filas resultado, respectivamente.
· Q1.1, Q1.2 y Q1.3 tienen tiempos de ejecución menores que las demás consultas porque tienen un único join mientras que las demás tienen al menos tres joins.
· Q4.1, Q4.2 y Q4.3 tienen cuatro joins y por eso se obtienen tiempos de ejecución mayores, excepto en Swarm64, porque cuanto mayor sea el conjunto de datos que haya que procesar, mejor es su rendimiento.
· Q3.3 y Q3.4 se ejecutan en un tiempo menor en Swarm64 porque devuelven 0 filas resultado.
· En general, se obtienen mejores tiempos de ejecución utilizando Clickhouse ya que está orientado a columnas mientras que con Citusdata, hay que utilizar tablas distribuidas o referenciadas (si la consulta es más compleja) y esto ralentiza los tiempos de respuesta. Al tener que utilizar almacenamiento columnar de índices con Swarm64, se deben crear los índices con las claves adecuadas sin que este tenga demasiadas ya que si no, se ralentizaría la consulta y deja de ser efectivo utilizar un índice.
5. Anotaciones sobre CitusData, Swarm64 y Clickhouse
CITUSDATA:
Si se utilizan tablas distribuidas se pueden hacer operaciones join entre dos tablas porque estas solo se pueden distribuir por un campo y tiene coincidir con el que aparece en la cláusula del join. Para hacer join entre varias tablas, se tiene que utilizar tablas referenciadas porque estas no se distribuyen por ningún campo específico.
La diferencia entre las tablas distribuidas y las referenciadas es que en las distribuidas se debe especificar un campo para realizar la distribución de la tabla en diferentes shards y las referenciadas no se distribuyen por ninguna columna concreta y solo se crea un shard por tabla. Los shards se almacenan en los nodos workers.
Cuando se utilizan tablas distribuidas, se tienen que crear para las tablas de hechos y de dimensión y si se utilizan tablas referenciadas, solo se tienen que crear aquellas que sean tablas dimensión.
Se utiliza la misma sintaxis que en SQL para realizar las operaciones básicas sobre una base de datos.
Para crear una tabla distribuida se utiliza el comando SELECT create_distributed_table(nombre tabla, columna) y para crear una referenciada, SELECT create_reference_table(nombre tabla).
SWARM64
Se utiliza la misma sintaxis que en SQL para realizar las operaciones básicas sobre una base de datos.
Se deben utilizar índices de almacenamiento por columnas (columnstore index) para mejorar el rendimiento.
La sintaxis de esta operación es: CREATE INDEX nombre_índice ON nombre_tabla USING columnstore (clave1, clave2, …)
CLICKHOUSE
Para crear una tabla, la sintaxis es la misma que en SQL pero hay que añadir ENGINE=().
Normalmente, se utiliza ENGINE=(MergeTree) y a continuación se debe añadir al menos una sentencia (PRIMARY KEY / ORDER BY / GROUP BY).
Para insertar valores con INSERT INTO se utiliza la misma sintaxis que en SQL pero si se quiere insertar los datos desde un fichero o con una consulta, se debe hacer desde fuera de Clickhouse con el siguiente comando:
clickhouse-client –format_csv_delimiter=”|” –query=”INSERT INTO nombre_tabla FORMAT CSV” <ruta_fichero
6. Conclusiones
Al realizar las consultas con PostgreSQL se obtienen tiempos de ejecución similares independientemente de la complejidad de las consultas mientras que con Citusdata, Clickhouse y Swarm64 sí varían.
Con Clickhouse se obtiene el mejor rendimiento en la mayoría de las consultas pero si se van a realizar consultas complejas sobre un conjunto de datos muy grande, se obtienen resultados ligeramente inferiores utilizando Swarm64.
El uso de Citusdata puede ser recomendable para la realización de consultas simples con un único join, ya que se podrían utilizar tablas distribuidas en vez de referenciadas y, aunque se obtendrían tiempos mayores que con Clickhouse o Swarm64, no serían tan elevados como para considerar el uso de Citusdata ineficiente. Sin embargo, si se requiere la realización de varios joins entre diferentes tablas, no sería eficiente el uso de Citusdata, ya que se obtienen tiempos muy elevados en comparación con las otras opciones.
Con Clickhouse se obtienen unos tiempos de ejecución aproximadamente 5 veces menores que con Citusdata en consultas simples y hasta 14 veces menores en consultas complejas; y con Swarm64 se obtienen tiempos aproximadamente 4 veces menores en las consultas más simples, 7 veces menores en las consultas con tres joins y 12 veces menores en las consultas con cuatro joins.
Por tanto, podemos concluir que se recomienda el uso de Clickhouse o Swarm64 ya que con ellas se obtienen los mejores resultados en cuanto a tiempo de ejecución en consultas complejas donde se tenga que procesar un volumen de datos elevado.