


1. INTRODUCCIÓN
El propósito de este documento es mostrar varios casos de uso del framework de Python Verticapy sobre la BD analítica Vertica.
Se van a tratar los aspectos generales que conciernen al uso de esta librería, comentando los aspectos positivos y negativos.
Se mostrarán los casos de uso que se podrían dar, así como un par de ejemplos prácticos programados en Python, donde se detallará cómo construir un modelo de clústeres y de random forest utilizando verticapy.
2. VerticaPy
Verticapy es una librería de Python enfocada a utilizar herramientas propias de entornos clásicos de Python, como funciones propias de pandas o scikit-learn, en un entorno en el que las ejecuciones sobre datos se procesan directamente en Vertica. Esto implica que los datos almacenados en ella en ningún momento se copian masivamente a la memoria de la máquina local donde trabajamos con Python, con lo que conseguimos que cuando se trabaja con cantidades ingentes de datos, la creación de modelos de Machine Learning que son computacionalmente muy costosos se puedan ejecutar en cuestión de segundos.
Hace poco os contábamos sobre las novedades de la última versión y como descargarlo
 Emilio
Emilio
3. Instalación
En este apartado se va a comentar todo lo referente al proceso de instalación de la librería Verticapy en el entorno de Python por defecto, que supondremos que es Anaconda.
En primer lugar, se debe acceder al repositorio de github de esta librería y nos la descargaremos en formato zip.
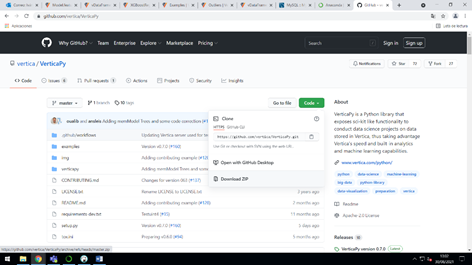
Paso seguido se descomprimirá el archivo zip en la ruta deseada, en mi caso “C:\Users\Administrator\OneDrive - stratebi.com\Documentos\Vertica”. Después debemos abrir una terminal desde Anaconda Navigator, con el entorno Python deseado.
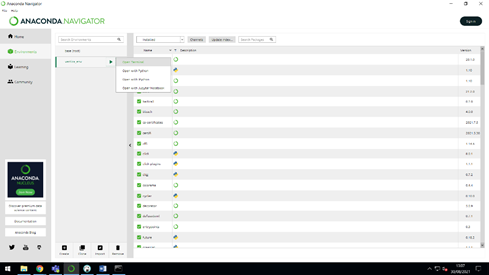
Una vez tenemos la terminal abierta, nos movemos a la ruta donde hemos descomprimido el zip anteriormente, utilizando el comando siguiente en mi caso:
“cd C:\Users\Administrator\OneDrive - stratebi.com\Documentos\Vertica\VerticaPy-master “.
Ahora, instalamos la librería mediante el comando:
“python setup.py install”.
Por último, podemos comprobar que la librería se encuentra ya disponible para ser utilizada ejecutando el comando:
“python -c "import verticapy; print(verticapy.__version__)"”. Si todo está funcionando correctamente se debería de mostrar por pantalla la versión que está corriendo de verticapy.
Cabe destacar que en mi caso se tuvo que reiniciar el PC para que el entorno reconociera la librería.
4. Ejemplos prácticos
En este apartado vamos a implementar dos modelos de Machine Learning en Vertica a través de la librería de Python verticapy. Nuestro entorno de trabajo constará de Jupyter Notebook con un entorno de Python 3.8.11 corriendo por debajo que contiene la librería verticapy.
Clustering sobre la dimensión cliente
En este ejemplo práctico vamos a crear un modelo de clústeres sobre la dimensión cliente, para agrupar a los clientes teniendo en cuenta los ingresos anuales, el género, la edad y la región dónde viven.
Primero de todo vamos a importar las librerías necesarias para este ejemplo y a indicar que queremos utilizar la magic function “%%sql” para hacer consultas sql desde Jupyter Notebook:

Ahora vamos a crear una conexión automática a la base de datos alojada en Vertica. Esta conexión será la utilizada cada vez que ejecutemos una consulta sql o hagamos referencia a los datos alojados en Vertica. En mi caso el código necesario para realizarla es:

A continuación, crearemos una tabla en Vertica con los datos que vamos a necesitar para entrenar nuestro modelo mediante la magic function “%%sql”:

Ahora vamos a definir un objeto vDataFrame que apuntará a nuestra tabla de Vertica que acabamos de crear:
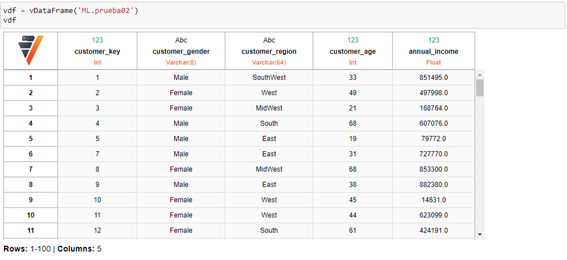
Para que el modelo de clustering funcione correctamente tenemos que crear variables dummies por cada categoría diferente de cada variable categórica, así como normalizar la variable anual_income. Además, la variable customer_age la vamos a transformar, definiendo tres grupos según la edad. De 18 a 30 años “joven”, de 30 a 65 “adulto” y de 65 a 120 ”mayor”. Estos grupos se han creado así tras un breve análisis exploratorio de los datos, donde nos damos cuenta que no existen registros de personas menores de 18 años. Todo esto se ejecuta con el código:
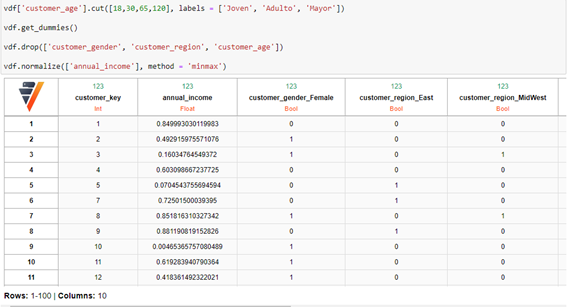
Elegimos ahora las columnas que utilizaremos, es decir, todas las de la tabla menos el customer_key:

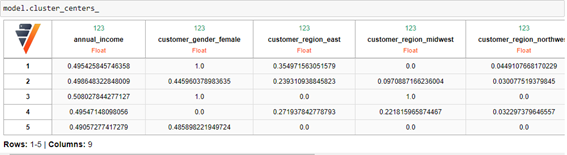
En este momento podemos crear ya el modelo de clustering, que en mi caso creará 5 clústeres, y ponerlo a entrenar con los datos:

Devolviendo los siguientes centros:
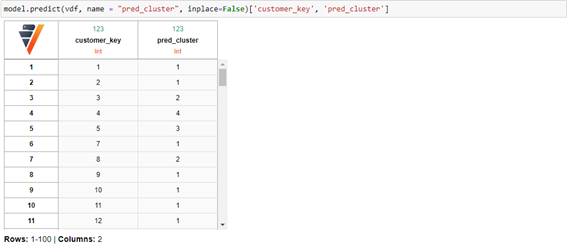
Por último, una vez que hemos entrenado el modelo podemos encontrar a qué clúster pertenecen los individuos de nuestra tabla o incluso predecir sobre individuos nuevos:
Random Forest con la dimensión producto
En este apartado vamos a implementar el código necesario para poner en funcionamiento un random forest.
Los datos que utilizaremos para entrenar dicho modelo se encuentran en la tabla “product_dimension” del esquema “public” de una base de datos local llamada “datawarehouse” y alojada en Vertica.
Primero de todo debemos importar las librerías que se van a utilizar e indicar que queremos utilizar la magic function “%%sql”, para poder ejecutar consultas sql desde el entorno de Python sobre Vertica:
A continuación, vamos a establecer una conexión automática a la base de datos en Vertica. Esta conexión será la utilizada cada vez que ejecutemos una consulta sql o hagamos referencia a los datos alojados en Vertica. En mi caso el código necesario para realizarla es:

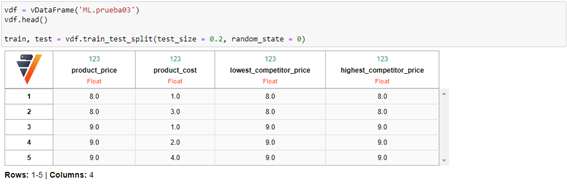
El random forest que vamos a entrenar trata de obtener el precio de un producto a partir del precio de coste, mayor precio de la competencia y menor precio de la competencia. Por tanto, vamos a crear una tabla en Vertica con estos datos de prueba:

Ahora vamos a crear un vDataFrame que apuntará a estos datos en Vertica, a partir del cuál obtendremos los vDataFrame “train” y “test”. Estos conjuntos necesarios para entrenar el modelo tienen una relación 80, 20 respectivamente y se construyen mediante el método “train_test_split” del objeto vDataFrame:
Ahora tan solo debemos crear el modelo random forest. En mi caso con 250 árboles obtenemos un resultado decente, por lo que el código para implementar este modelo es el siguiente:
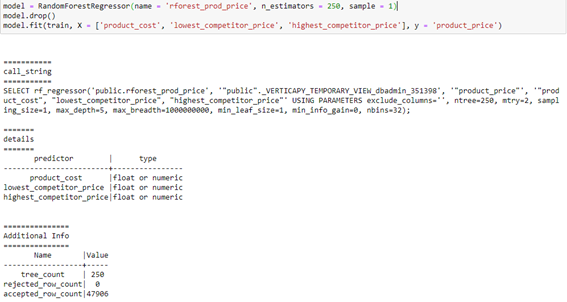
Verticapy nos proporciona a través de la clase de random forest la posibilidad de obtener el esquema de la importancia de variables, donde vemos que el coste del producto es insignificante para predecir el precio del producto. Mientras que el mayor precio de la competencia es el factor más significativo:

Una vez el modelo está entrenado, predecimos sobre el conjunto test:
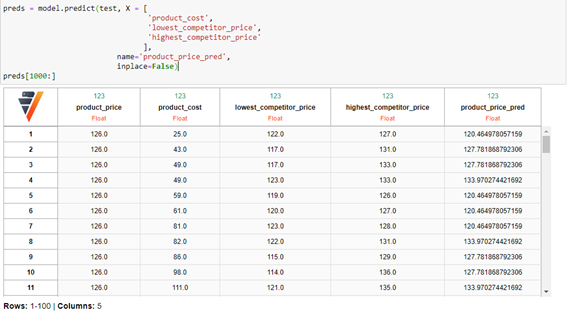
obteniendo un error cuadrático medio (mse):
5. Aspectos negativos de VerticaPy
Aunque algunas de las clases más utilizadas de pandas y scikit-learn están “incluidas” en Verticapy (no son exactamente las mismas), cuando se hace uso de ellas se encuentran varios problemas. El primero es que al estar trabajando con los datos directamente de la base de datos, para transformar datos de tipo texto se debe utilizar alguna de las escasas funciones que proporciona Verticapy, ya que no se puede hacer un casteo sin más a tipo string de Python.
Otro de los problemas que encontramos es que las clases que se han portado a verticapy de scikit-learn se dejan algunos parámetros por el camino, por ejemplo RandomForestRegressor no te permite cambiar algo tan sencillo e importante como la función de error. De este ejemplo surge otro problema, la documentación de las clases de Verticapy. Si accedemos a la documentación de RandomForestRegressor no encontramos qué función de error está utilizando el modelo, por lo que cuando se utiliza este modelo vamos a “ciegas”.
6. Casos de uso de VerticaPy
Teniendo en cuenta los aspectos positivos y negativos comentados anteriormente, encuentro algún caso de uso que considero que se le podría dar a dicha librería. El primero surge en la fase de creación de un modelo de Machine Learning, cuando nos preguntamos si un modelo funcionará bien para un conjunto de datos en concreto. Aprovechando la velocidad de creación y entrenamiento de modelos con esta librería, se puede utilizar verticapy para, de una manera rápida, implementar un modelo y observar los resultados para determinar si es abordable el problema o si, en cambio, se necesita aplicar otra perspectiva. Aunque en caso de determinar que el modelo estadístico predictivo es factible, considero que si lo que se busca es una solución robusta y potente, verticapy en su versión actual no es la opción más adecuada debido a la falta de flexibilidad que se necesita para construir un modelo correctamente, seguramente esto ira cambiando en próximas versiones.
Otro caso en el que verticapy podría ser de ayuda es cuando en un proceso se pretenda leer o incluso transformar/limpiar datos alojados en Vertica, ya que esta librería nos agiliza estas tareas utilizando la sintaxis de Python.
7. Conclusión
Verticapy es una herramienta con una gran proyección, puesto que tener las funciones de librerías como pandas o scikit-learn a disposición de ser utilizadas directamente sobre la base de datos en Vertica permite ahorrar bastante tiempo de ejecución en tareas de Machine Learning o procesamiento de datos.
No obstante, es cierto que hoy en día vemos como todavía se encuentran en fase de desarrollo multitud de clases de esta librería y esto se refleja en un catálogo de funciones pobre, donde no se llega ni mucho menos a la flexibilidad que sklearn o pandas proporciona sobre un entorno Python original.
En un futuro, tal vez se consigan implementar las clases más utilizadas al completo, proporcionando un nuevo paradigma en el que ya no será útil volcar los datos desde Vertica a una máquina local para utilizar librerías de Python de procesamiento y analítica de datos. Si no que mediante código sencillo en Python, podremos enviar a Vertica las instrucciones necesarias para crear cualquier modelo en la máquina origen donde la base de datos está desplegada.
Creado por el equipo de Data Ninjas de Stratebi