


However, when we work with data sources with Big Data features (Volume, Variety and Velocity), our metrics tables (e.g. sales volume, units...) and those tables that describe the context (e.g. date, customer, product) could store billions of rows , making the processing requirements very high, even for the most advanced Big Data technologies.
**Download free 27 pages whitepaper ''Big Data Analytics benchmark'
**Download free 27 pages whitepaper ' 'Big Data Analytics benchmark'
In order to support OLAP applications with Big Data, multiple technologies that promise excellent results have emerged in recent years. Some of the best known are Apache Kylin, Vertica, Druid, Google Big Query or Amazon Red Shift .
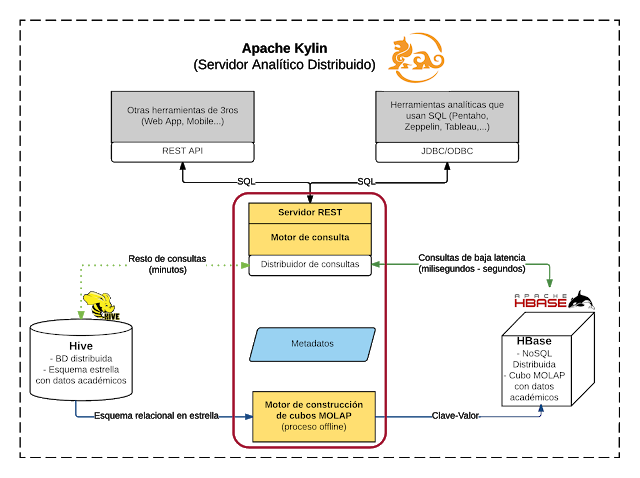
In this whitepaper we describe the Big Data OLAP technologies that are part of the benchmark: Apache Kylin and Vertica .
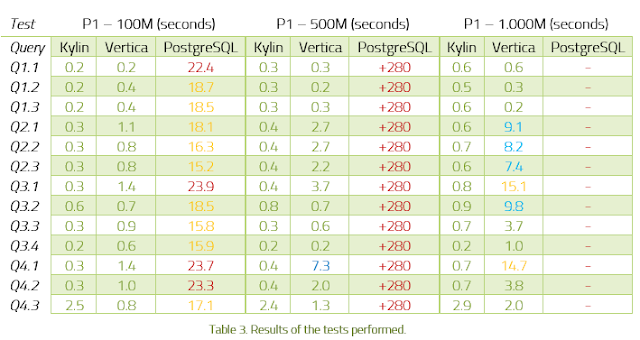
Besides comparing these technologies against each other, we have also compared them with the relational database PostgreSQL .
This open source technology, despite not being a Big Data database, usually offers very good results for traditional OLAP systems. Therefore, we considered worthwhile to include PostgreSQL in order to measure the differences of it against Kylin and Vertica in a Big Data OLAP scenario
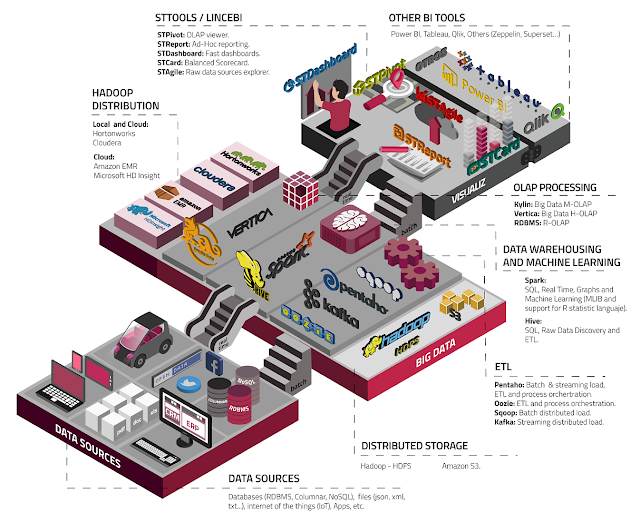
LinceBI , open source based analytics solution, use this technologies for scalable and faster performance on Business Intelligence
More Info:
OLAP for Big Data. It´s possible?

Hadoop is a great platform for storing a lot of data, but running OLAP is usually done on smaller datasets in legacy and traditional proprietary platforms. OLAP workloads are beginning to migrate to the one data lake that is running Hadoop and Spark. Fortunately, there are a number of Apache projects that are starting to make OLAP possible on Hadoop. Apache Kylin For an introduction to this interesting Hadoop project, check...