


En el mundo de ciencia de datos, en Python son indispensables dos librerías que introducen las estructuras fundamentales para representar y manipular los datos: numpy con su array N-dimensional y pandas con su Series y DataFrame. Son la base de cualquier software científico y de análisis de datos, como SciPy o Scikit-learn.
xarray es una librería desarrollada con el objetivo de proporcionar etiquetas (labels) a los datos numéricos que proceden de un array de numpy. xarray no solo almacena estas etiquetas como una propiedad descriptiva de los datos, sino que las utiliza para realizar acciones de una manera clara y concisa. Por ejemplo: aplicar operaciones o seleccionar valores por nombre de dimensión: x.sum(‘time’) realiza la suma a lo largo de la dimensión time, o x.sel(time=’2014-01-01’) devuelve el valor cuya dimensión time es ‘2014-01-01’. Esto consigue escribir una menor cantidad de código y que el código sea mucho más explicativo, a diferencia de realizar esas mismas operaciones por ejes numéricos.
La filosofía de desarrollo de la librería tiene fijación en la funcionalidad e interfaces sobre datos etiquetados, y aprovechar la potencia de otras librerías para tareas relacionadas, como numpy, pandas, matplotlib (para visualización de datos) … Además, se tiene muy en cuenta la compatibilidad con estas librerías, de manera que se facilita mucho la conversión entre formatos xarray y pandas. Como aplicación de esto, es posible trabajar con xarray para manipular los datos y exportar cualquier parte del conjunto de datos a un objeto de pandas.
Aunque pandas es excelente para el procesamiento y análisis de datos estructurados y etiquetados de baja dimensión, que pueden representarse de manera tabular (filas y columnas), xarray permite procesar y etiquetar datos de dimensión mayor, como puede ser una serie temporal o imágenes (representadas como un tensor de 3 dimensiones).
ESTRUCTURAS DE DATOS
xarray tiene dos estructuras fundamentales de datos, construidas y basadas en numpy y pandas: DataArray y Dataset. DataArray es la implementación de un array n-dimensional etiquetado, puede considerarse una extensión n-dimensional de pandas.Series. Dataset es un contenedor de DataArrays, de manera similar a un diccionario. Es el análogo de pandas.DataFrame en xarray. Dataset permite, además de coger DataArray por nombre, seleccionar o combinar datos a lo largo de una dimensión compartida por los DataArray.
INSTALACIÓN
Para instalar xarray es necesario tener instaladas las dependencias numpy y pandas. Esto puede hacerse mediante conda o pip. Con pip es suficiente con escribir el comando, una vez se tienen instaladas las dependencias necesarias
pip install xarray
Una vez instalado se importa xarray con la abreviatura xr por convenio.
CONSTRUCCIÓN DE DATAARRAY Y DATASET
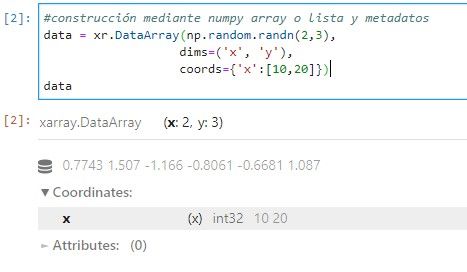
Un DataArray puede construirse mediante un array de numpy o lista y proporcionarle los metadatos correspondientes (dimensiones, coordenadas), o bien mediante un panda.Series o panda.DataFrame y el DataArray copiará directamente los metadatos.
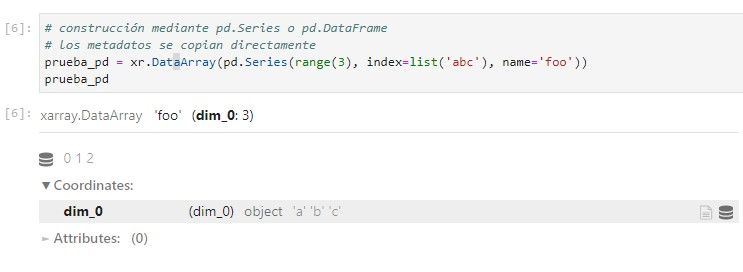
Al no proporcionarle nombre a la coordenada, pandas le asigna el nombre ‘dim_0’ por defecto, y xarray absorbe esa configuración.
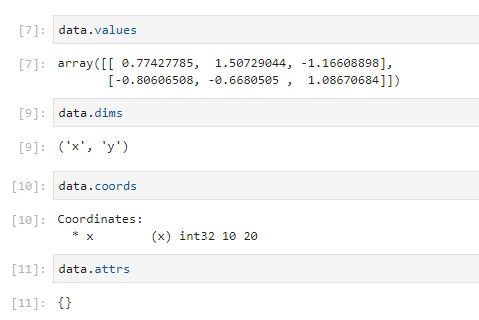
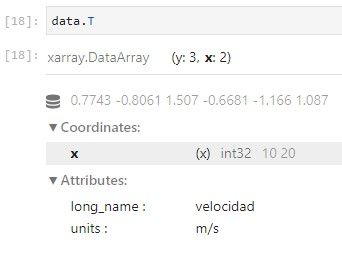
Las propiedades principales de un DataArray son: values (array de numpy que puede modificarse), dims, coords y attrs.
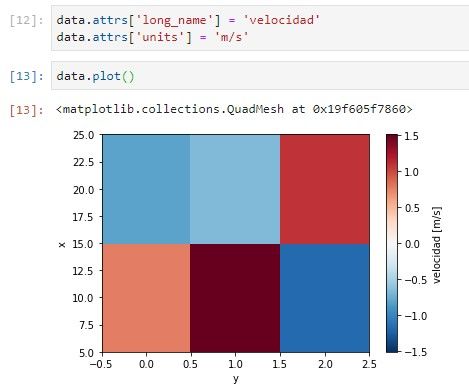
Configuración de atributos: data.attrs[‘long_name’], data.attrs[‘units’] los coge automáticamente para etiquetar los gráficos. También se pueden añadir atributos a las coordenadas.
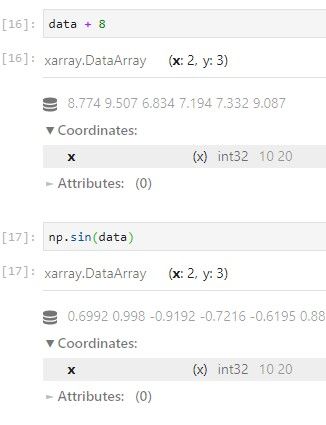
Cálculos con DataArray:
Funcionan de manera similar a numpy
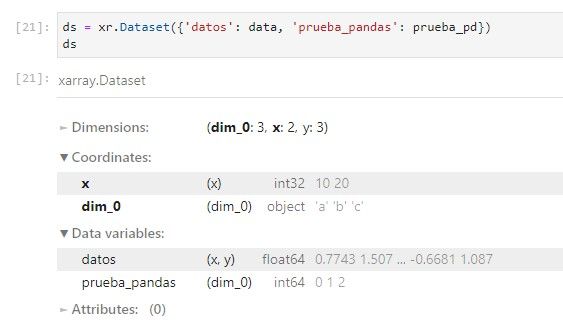
Los Datasets pueden crearse mediante un diccionario de DataArrays. Se puede acceder a los DataArray de un Dataset mediante indexación como un diccionario o bien como propiedad. Sin embargo, la asignación solo funciona con indexación de diccionario.
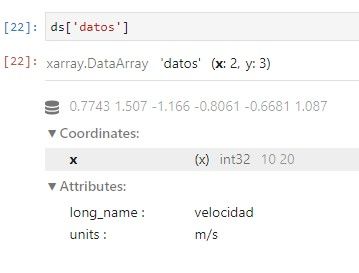
TRANSFORMACIÓN A PANDAS
Transformar a objetos de pandas y desde objetos de pandas se hace de manera muy sencilla, ya hemos visto que el constructor de DataArray acepta un panda.Series, con los siguientes métodos se transforma de vuelta a objeto pandas.
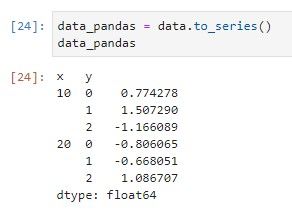
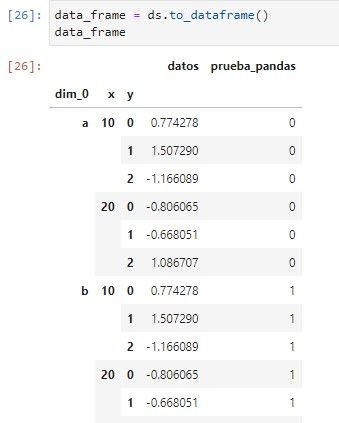
SELECCIONAR valores
xarray tiene soporte para cuatro métodos de indexación:
· posicional y por etiqueta de entero, como numpy
· “localización” (loc): posicional y etiqueta de coordenada, como pandas
· “selección de enteros” (isel): por nombre de dimensión y etiqueta de entero
· “selección” (sel): por nombre de dimensión y etiqueta de coordenada
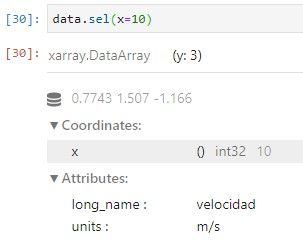
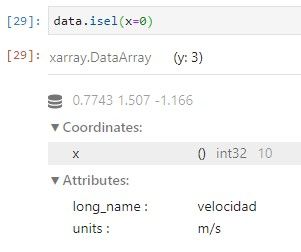
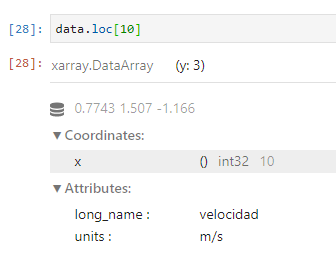
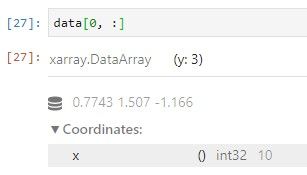
APLICACIÓN DE FUNCIONES AGREGADAS
Por razones de consistencia, las funciones agregadas de xarray devuelven un DataArray, por ejemplo:
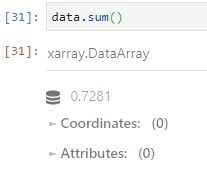
Para obtener el escalar podemos utilizar el método ítem
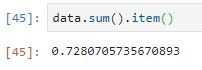
xarray permite aplicar funciones de agregado a lo largo de dimensiones por nombre, en lugar de tener que escribir el entero que representa el eje de esa dimensión.
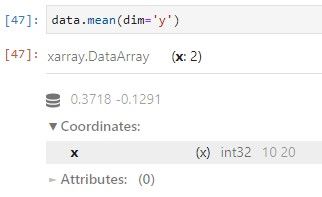
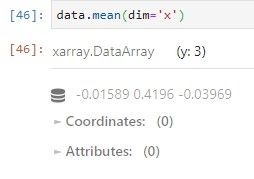
CASO PRÁCTICO
Como último ejemplo, vamos a generar un dataset de temperaturas mínimas y máximas a lo largo de un año en tres localizaciones.
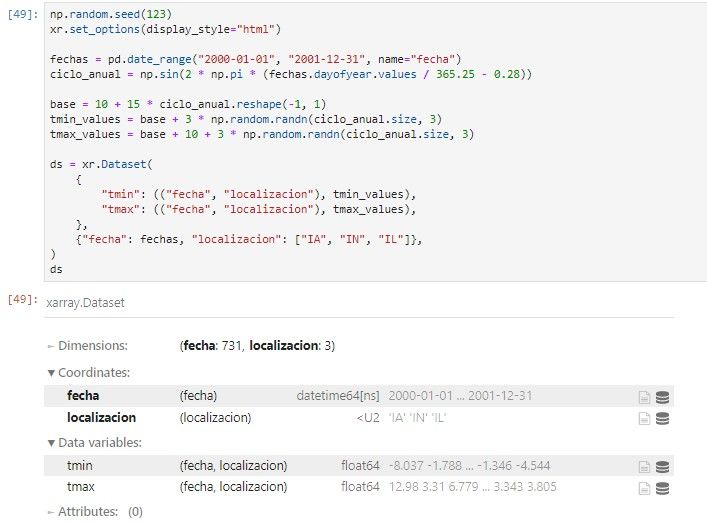
Gracias a que xarray permite etiquetar las dimensiones, se facilita la sintaxis para realizar ciertos cálculos de interés para analizar estos datos.
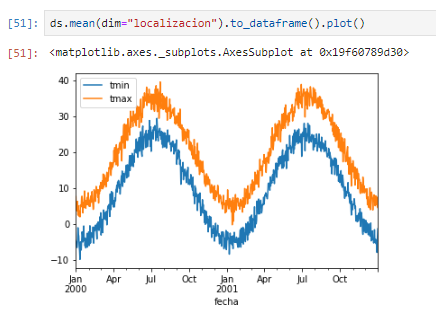
Visualizar la temperatura media de las 3 localizaciones
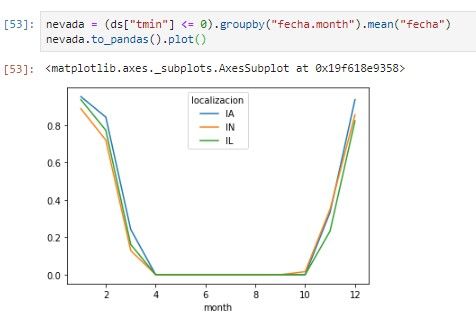
Probabilidad de nevada por mes:
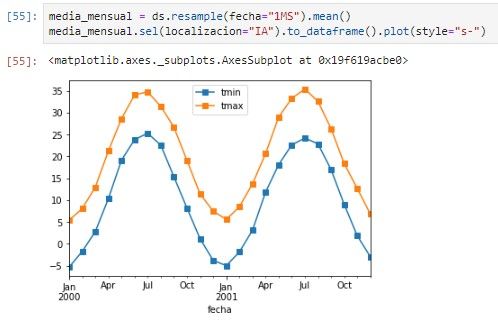
Temperatura media mensual:
Como se ha puesto de manifiesto en estos ejemplos, xarray no solo etiqueta las dimensiones, sino que les aporta funcionalidad a la hora de filtrar los datos o aplicarles una función de agregado.
CONCLUSION
xarray es una librería popular para el uso del análisis de datos de las geociencias por la naturaleza multidimensional de los datos en los que se trabajan (dimensiones espaciales, datos como precipitaciones, temperaturas, dimensiones temporales…).
Bajo estas condiciones, xarray proporciona una interfaz para el manejo de este tipo de datos donde prima la claridad y la concisión del código, si se le dedica el tiempo necesario a aprender una manera correcta de trabajar con la librería. Por suerte, dado que podemos considerar xarray como una extensión de numpy y pandas, las dos librerías base de ciencia de datos en Python, aquellos usuarios que ya tengan un manejo de estas encontrarán la curva de aprendizaje mucho más suave.