

PyCaret es una librería low-code de machine learning open-source en Python que automatiza los workflows de Machine Learning.
1. Introducción
El propósito de este documento es investigar casos de uso de la librería de Python PyCaret. Además se pondrá un ejemplo de estos y se dará una opinión al respecto del framework en cuestión.
2. PyCaret
PyCaret es una librería de Python que permite llevar a cabo desde la preparación de los datos, hasta el despliegue del modelo final en tan solo unos minutos. Esta librería es compatible con cualquier tipo de notebook de Python, y además nos permite realizar comparaciones de varios modelos automáticamente.
A modo de ejemplo vamos a crear un Jupyter Notebook que sea capaz, en tan solo unas líneas, de leer los datos, procesarlos obteniendo un ranking de modelos de ML, entrenar el modelo más potente y desplegarlo para obtener predicciones sobre datos.
Primero vamos a instalar PyCaret en nuestro entorno de Python, para ello ejecutamos el siguiente comando en una terminal:
‘pip install pycaret’
Paso seguido abrimos un notebook de Jupyter y hacemos los siguientes imports:

Utilizaremos un conjunto de datos proporcionado por PyCaret llamado ‘credit’, para importarlo corremos el siguiente código:
Vemos como disponemos de 24000 filas con 24 columnas cada una:

Ahora vamos a particionar el conjunto de datos, obteniendo el 95% para entrenar el modelo:
El 5% restante lo vamos a utilizar para comprobar el rendimiento del modelo sobre datos nunca antes vistos:
Como podemos ver, tenemos varios predictores que se utilizarán para predecir la variable binaria ‘default’.
Lo último que haremos para limpiar los datos es resetear los índices de cada subconjunto de datos:

Ahora vamos a comparar el rendimiento de distintos modelos. Para ello debemos, en primer lugar, importar:

Paso seguido definimos el entorno de PyCaret con los datos de entrenamiento, esto hará que cada vez que llamemos a un modelo a entrenar se escojan dichos datos para entrenar. Además este proceso también preprocesa los datos automáticamente de manera que sea más fácil aplicar los modelos estadísticos:
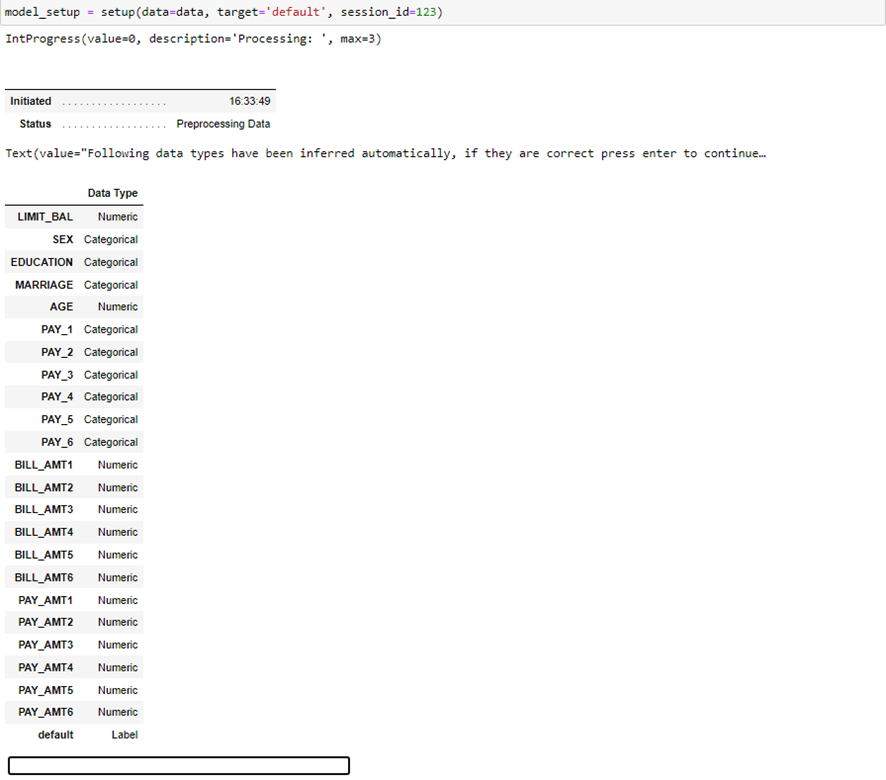
Vemos como la ejecución de esta consulta es interactiva, pues espera que comprobemos que los tipos de datos inferidos automáticamente sean los correctos, en tal caso pulsamos enter. Entonces se nos mostrarán los cambios realizados a los datos de entrenamiento que hemos realizado
Podemos ver los modelos de clasificación de que dispone PyCaret, mediante el siguiente comando:
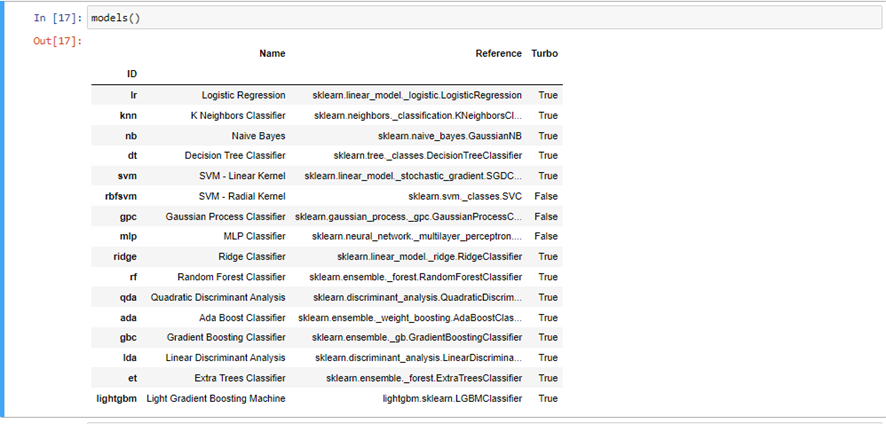
Este output es importante puesto que se necesitan los id de cada modelo para trabajar con ellos más en específico, como veremos a continuación.
Una de las funciones más útiles de esta librería nos permite comparar todos los modelos anteriores, esta función es la siguiente:
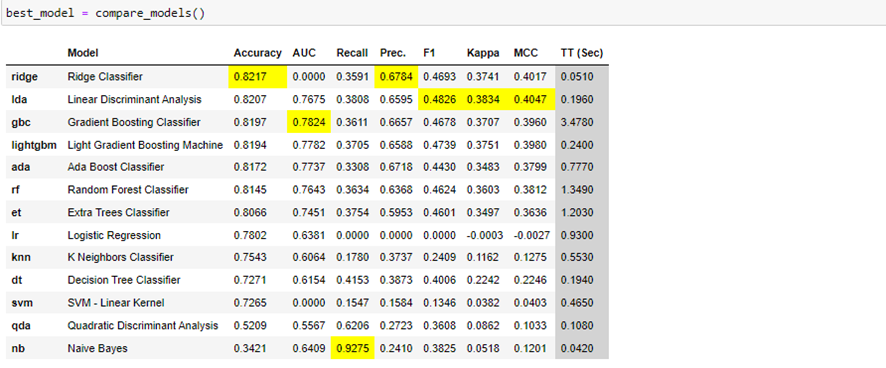
Mediante esta tabla podemos escoger el modelo que más nos convenga, teniendo en cuenta las diferentes puntuaciones sobre las métricas que se muestran.
En nuestro caso, por ejemplo vamos a construir y entrenar un random forest sobre los datos de entrenamiento. Para ello ejecutamos:
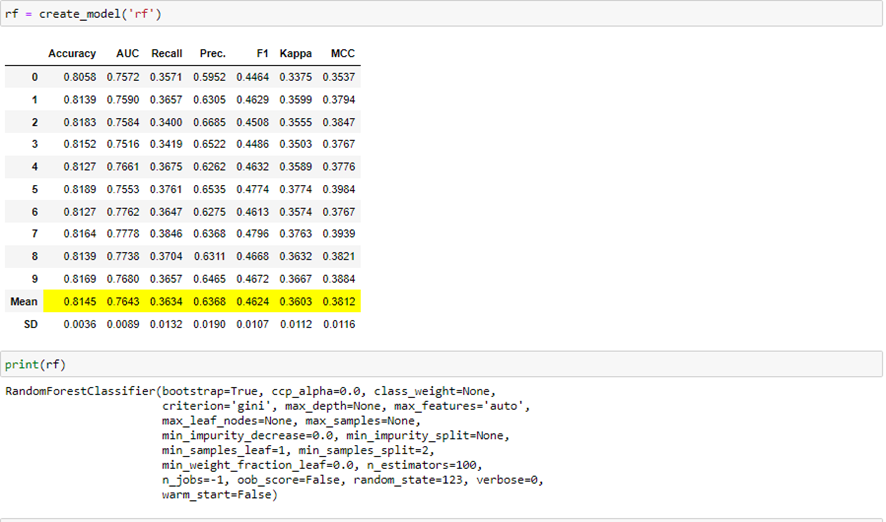
Podemos ver como ha entrenado 10 modelos distintos, para poder obtener los detalles de este modelo en media y, así, poder extrapolar los resultados en mayor detalle. También se pueden ver los hiperparámetros con los que el modelo ha sido entrenado.
Para mejorar este modelo, es decir, obtener los hiperparámetros óptimos o que más se aproximan a estos, podemos correr la siguiente función, que entrena 10 modelos distintos 10 veces cada uno, y devuelve el que mejor precisión media obtenga:
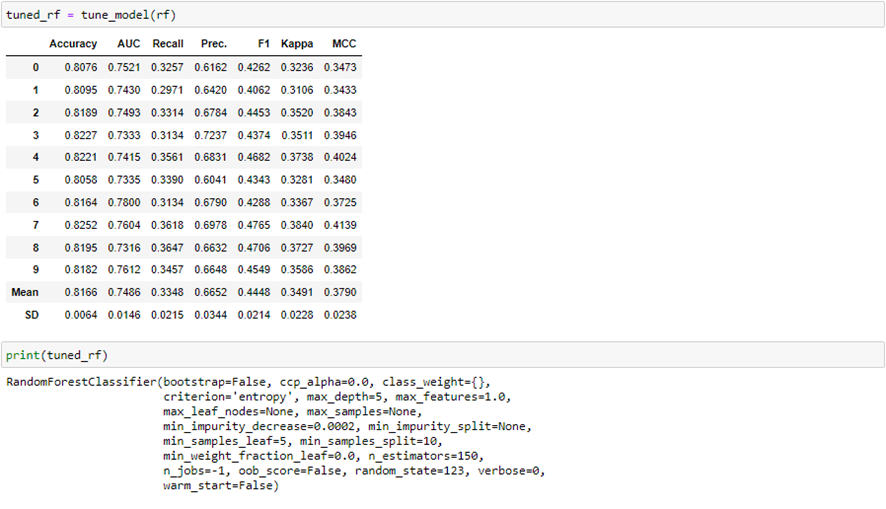
Podemos ver como algunos hiperparámetros se han modificado, de manera que obtenemos una mayor precisión media.
Una vez se ha entrenado el modelo específico, si estamos interesados en saber cómo se comporta, se puede por ejemplo estudiar su tasa de verdaderos positivos y falsos positivos, con el gráfico de curvas ROC:
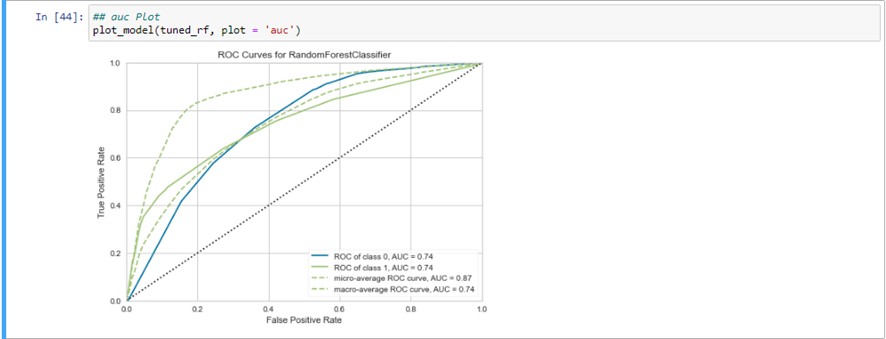
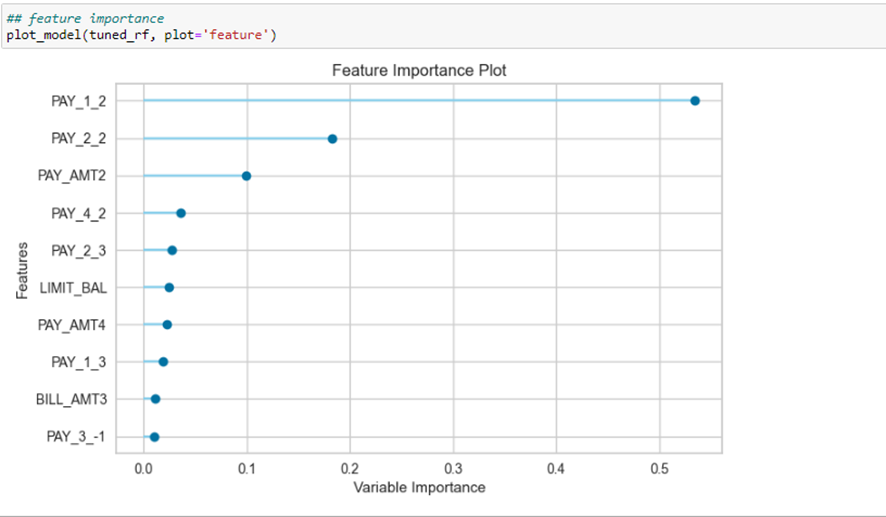
Igual de interesante es el gráfico de importancia de variables, para poder obtener conclusiones sobre las variables que más afectan a nuestra variable objetivo:
Llegados a este punto, podemos obtener predicciones sobre el conjunto de datos test, que no ha sido utilizado para entrenar el modelo:
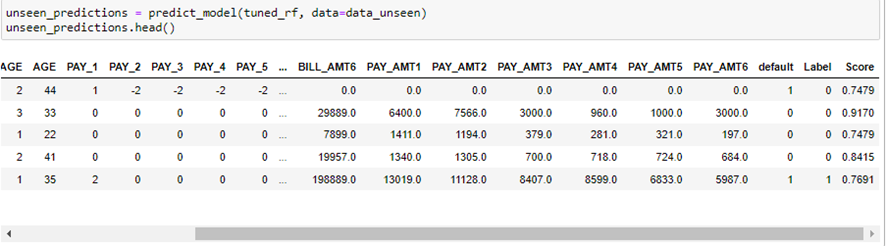
Como podemos ver, se crean dos columnas nuevas. Label hace referencia a la predicción realizada mientras que Score es la probabilidad asociada a la predicción.
Por último, para terminar de configurar nuestro modelo random forest, debemos finalizar el modelo, es decir, se va a entrenar con todo el conjunto de datos del que se dispone:
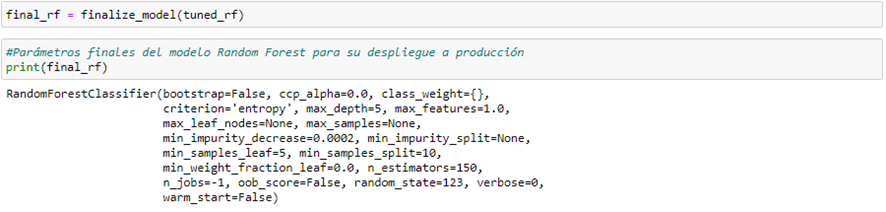
De esta manera, el modelo está listo para su puesta en producción, por tanto podemos guardarlo localmente mediante:
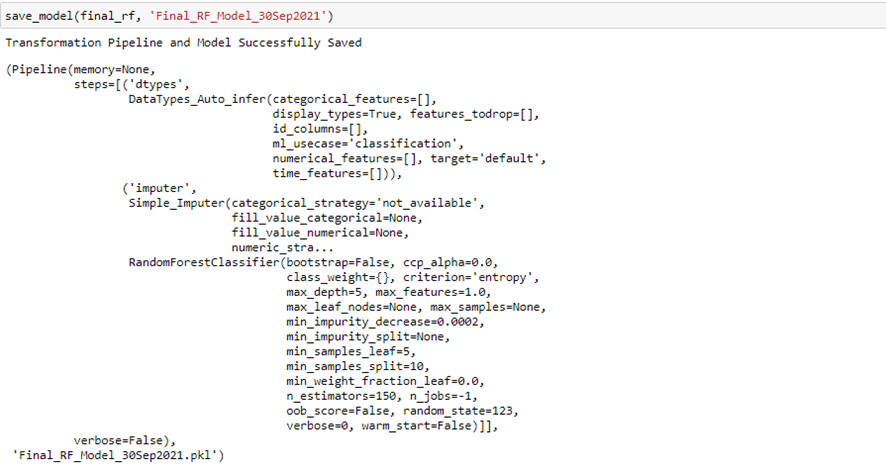
Al igual que cargarlo posteriormente, de tal manera que el modelo está preparado para utilizarse y predecir al momento:

Con el PyCaret explainer Dashboard, como nueva funcionalidad, permite una visualización mucho más potente
3. Conclusión
Como hemos podido comprobar, PyCaret proporciona un entorno de trabajo hábil y potente que facilita la obtención de un buen modelo predictivo, así como una buena configuración de éste.
Además, se pueden guardar los modelos entrenados con todo el conjunto de datos y hacer uso de ellos en cualquier momento, sin la necesidad de volver a entrenarlos.
Como es habitual en este tipo de herramientas, el ajuste de un modelo más complejo para abordar grandes problemas de predicción se debe hacer con herramientas como sklearn o tensorflow, aunque esto no quita que PyCaret nos sirva para elegir rápidamente un modelo que, a priori, ajusta bien los datos.
De igual manera, se puede utilizar para obtener ideas sobre qué parámetros ajustar en un modelo específico que se esté desarrollando manualmente.
| Important Links | |
|---|---|
| New to PyCaret? Checkout our official notebooks! | |
| Example notebooks created by community. | |
| Tutorials and articles by contributors. | |
| The detailed API docs of PyCaret | |
| Our video tutorial from various events. | |
| Cheat sheet for all functions across modules. | |
| Have questions? Engage with community and contributors. | |
| Changes and version history. | |
| PyCaret's software and community development plan. |
Te puede interesar:
 Emilio
Emilio EmilioEmilio
EmilioEmilio Emilio
Emilio EmilioEmilio
EmilioEmilio Admin
Admin Emilio
Emilio